| |
Your first midterm examination will appear here. It covers Chapters 1 - 5, omitting Section 3.6 (we'll cover that with networking) and Sections 5.9 & 10.
It will be a 50 minute, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Section and page number references in old exams refer to the edition of the text in use when that exam was given. You may have to do a little looking to map to the edition currently in use. Also, which chapters were covered on each exam varies a little from year to year.
Some questions may be similar to homework questions from the book. You will be given a choice of questions. I try to ask questions I think you might hear in a job interview. "I see you took a class on Operating Systems. What can you tell me about ...?"
Preparation hints:
Read the assigned chapters in the text. Chapter summaries are especially helpful. Chapters 1 and 2 include excellent summaries of each of the later chapters.
Read and consider Practice Exercises and Exercises at the end of each chapter.
Review authors' slides and study guides from the textbook web site.
Review previous exams listed above.
See also Dr. Barnard's notes. He was using a different edition of our text, so chapter and section numbers do not match, but his chapter summaries are excellent.
Read and follow the directions:
- Write on four of the five questions. If you write more than four questions, only the first four will be graded. You do not get extra credit for doing extra problems.
- Each problem is worth 25 points.
- In the event this exam is interrupted (e.g., fire alarm or bomb threat), students will leave their papers on their desks and evacuate as instructed. The exam will not resume. Papers will be graded based on their current state.
- Read the entire exam. If there is anything you do not understand about a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of paper [or -5].
- Be sure your name is on each sheet of paper you hand in [or -5]. That is because I often separate your papers by problem number for grading and re-assemble to record and return.
- Write only on one side of a sheet [or -5]. That is because I scan your exam papers, and the backs do not get scanned.
- No electronic devices of any kind are permitted.
- Be sure I can read what you write.
- If I ask questions with parts
- . . .
- . . .
your answer should show parts in order
- . . .
- . . .
- The instructors reserve the right to assign bonus points beyond the stated value of the problem for exceptionally insightful answers. Conversely, we reserve the right to assign negative scores to answers that show less understanding than a blank sheet of paper. Both of these are rare events.
The university suggests exam rules:
- Silence all electronics (including cell phones, watches, and tablets) and place in your backpack.
- No electronic devices of any kind are permitted.
- No hoods, hats, or earbuds allowed.
- Be sure to visit the rest room prior to the exam.
In addition, you will be asked to sign the honor pledge at the top of the exam:
"I recognize the importance of personal integrity in all aspects of life and work. I commit myself to truthfulness, honor and responsibility, by which I earn the respect of others. I support the development of good character and commit myself to uphold the highest standards of academic integrity as an important aspect of personal integrity. My commitment obliges me to conduct myself according to the Marquette University Honor Code."
Name _____________________________ Date ____________
Score Distribution:

Median: 75; Mean: 73.5; Standard Deviation: 15.3
These shaded blocks are intended to suggest solutions; they are not intended to be complete solutions.
Problem 1 Definitions
Problem 2 Test-Driven Development
Problem 3 AppDev: Proceeses vs. Threads
Problem 4 Semaphores and Mutual Exclusion
Problem 5 Fork BOMB -- Many fork()s
Problem 1 Definitions
Give careful definitions for each term (in the context of computer operating systems):
- Batch system
- Message passing systems
- IPC
- Time sharing system
- Kernel mode
Warning: A definition that starts "Z is when ...," or "Z is where ..." earns -5 points.
Vocabulary list. I ask mostly about terms that appear as section, subsection, or subsubsection headings in the text, but any phrase printed in blue in the text is fair game. Here are some of the terms I might ask you to define. This list is not exhaustive:
- Batch system: Typically large, run at off-peak times, with no user present. E.g., overnight accounting runs, daily update of Checkmarq records. Batch mode is an old business data processing mode, still VERY widely used in mainframe business data processing. TABot is a batch system.
- Blocking receive vs. Non-blocking receive: [Section 3.4.2.2.]
- Blocking send vs. Non-blocking send: [Section 3.4.2.2.] Spell "receive" correctly.
- Busy waiting [p. 213]. Waiting while holding the CPU, typically waiting by loop, doing nothing. For example
while (TestAndSet(&lock) ; // Does nothing
A process in a Waiting state (in the sense of the Ready-Running-Waiting state diagram) is not busy waiting because it is not holding the CPU.
- Client-Server computing and Peer-to-peer computing: [Section 1.11.4 & 5.] Client-server is a master-slave relationship. Client requests, server answers. Which is the master?
- Clustered systems: [Section 1.3.3] Two or more individual (computer) systems gathered together to accomplish computational work.
- Interactive system: Typically, a user is present.
- Embedded system: A dedicated function within a larger mechanical or electrical system, often with real-time computing constraints.[1][2] It is embedded as part of a complete device often including hardware and mechanical parts. Embedded systems control many devices in common use today. -- Wikipedia.
- Deadlock vs. starvation [p. 217]. Both concern indefinite wait. "A set of processes is in a deadlocked state when every process in the set is waiting for an event that can be caused only by another process in the set." Starvation is also an indefinite wait not satisfying the definition of deadlock, often due to an accidental sequence of events.
- IPC: [Sect. 3.4 & 3.5] Interprocess Communication: shared memory and message passing. It
is important to know at least some of the TLAs (Three Letter Abbreviations).
- Kernel: [P. 6] Part of the OS that is running all the time, core OS processes.
- Kernel node vs. user mode: States of the processor. Normally, the processor is in user mode, executing instructions on behalf of the user. The processor must be in kernel mode to execute privileged instructions.
- Kernel thread: [Section 4.3] Created by OS processes.
- Kernighan's Law: [P. 87] "Debugging is twice a hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it." You should recognize the name Kernighan as one of the authors of our C textbook
- Message passing systems: [Sect. 3.3.4.2] A mechanism to allow processes to communicate and to synchronize their actions without sharing the same address space. A message-passing facility provides at least two operations: send(message) and receive(message). Be careful to avoid circular definitions: "Message passing systems pass messages" counts zero points. "recieve" earns -2 points.
- Non-blocking receive: [Section 3.4.2.2] Receive a message. If no message is there, return from the receive() function all immediately.
- Operating system: [P. 3] A program that manages the computer hardware, provides a basis for application programs, and acts as an intermediary between the computer user and the computer hardware.
- Operating system calls: [Section 2.3] An interface to operating system services made available to applications software by an operating system.
- Priority inversion [p. 217]: A high priority process is forced to wait for a lower priority process to release some resource(s).
- Race condition [p. 205]: Several processes access and manipulate the same data concurrently, and the outcome depends on what happens to be the order of execution.
- POSIX: Portable Operating System Interface. We looked at POSIX examples for shared memory, message passing, and Pthreads.
- Pipes: [Sect. 3.6.3] A pipe acts as a conduit allowing two processes to communicate. A pipe is usually treated as a special type of file, accessed by ordinary read() and write() system calls.
- Privileged instructions: [P. 22] Some hardware instructions that may cause harm. May be executed only in kernel mode. Examples: Instruction to switch to kernel mode, I/O control, timer management, interrupt management
- Process: [P. 105] Program in execution, a unit of work in a modern time-sharing system.
- Process Control Block (PCB): [Section 3.1.3] Representation of a process in the operating system.
- Process scheduling: [Section 3.2] Switch between processes so frequently that users can interact with each process. Select a process from the Ready list for execution in the CPU.
- Process State: [Sect. 3.1.2] Defined by the current activity of the process. Each process may be in one of: New, Running, Waiting, Ready, Terminated.
- Process vs. Thread: [P. 105-106, 163] A process is a program in execution. A process may include several threads. A thread is a basic unit of CPU use. It includes a thread ID, a program counter, a register set, and a memory stack.
- Protection vs. Security: [Section 1.9.] Protection - Mechanisms for controlling access to the resources provided by a computer system. Protection controls access to computer system resources. Security defends a system from internal and external attacks. Protection <> Security.
- Real-time system: [Section 1.11.8] Typically time-sensitive interaction with external devices.
- RPC (in context of inter-process communication): [Sect. 3.6.2] Remote Procedure Calls abstract the procedure-call mechanism for use between systems with network connections using message-based communication.
- Shared memory systems: [Sect. 3.4.1] A region of memory residing in the address space of two or more cooperating processes. "Shared memory is memory that is shared" is circular.
Alternative: Separate CPUs that address a common pool of memory
- Shared memory vs. Message passing: [Section 3.4.] Be careful to avoid circular definitions: "Shared memory is memory that is shared" counts zero points.
- Sockets: [Sect. 3.6.1] An endpoint for communication. A pair of processes communicating over a network employs a pair of sockets. A socket is identified by an IP address and a port number.
- Symmetric multiprocessing (SMP): [P. 15] Multiprocessing system in which each processor performs all tasks within the operating system. Does your "definition" hold also for asymmetric?
- Thread cancelation: [Sect. 4.6.3] Task of terminating a thread before it has completed.
- Thread library: [Section 4.4] Provides a programmer with an API for creating and managing threads.
- Thread-Local Storage: [ 4.6.4] Data of which each thread must keep its own copy. Do not confuse with local variables.
- Thread pool: [Sect. 4.5.1] Create a number of threads at process startup and place them in a pool, where they sit and wait for work.
- Time sharing: [P. 20] The CPU executes multiple jobs by switching among them, but the switches happen so frequently that the users can interact with each program while it is running.
- User mode vs. Kernel mode: [Section 1.5.1] User mode is a state of the operating system in which most instructions of user applications are executed. Kernel mode is a state of the operating system in which some critical portions of the operating system is executed. What is it called when a user process makes an operating system call for service? Most operating system code is executed in user mode.
- User thread: [Section 4.3] Created by user processes.
- Virtual machine: [Section 1.11.6] Abstract the hardware of a single computer into several different execution environments, creating the illusion that each computing environment is running its own private computer.
Problem 2. Test-Driven Development - Priority Queue
In Project 5, you are building and testing a Priority Queue.
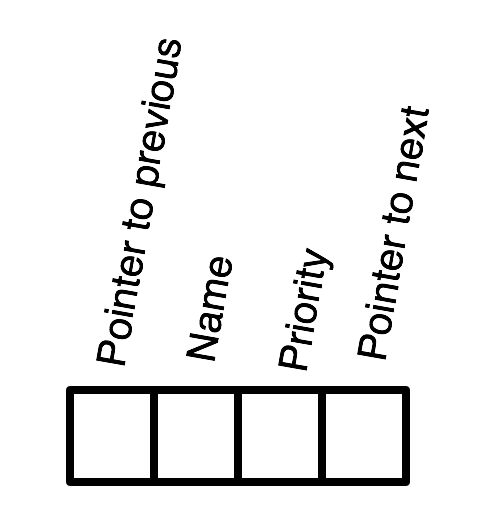
For the purposes of this question, assume that the Priority Queue is a doubly linked list.
The queue is accessed via Head and Tail pointers.
Priorities are nonnegative integers.
The Priority Queue is sorted with higher priorities closer to the Head.
Each node has four fields, depicted graphically as
Write EIGHT appropriate test cases for INSERTION into this Priority Queue. Your test cases should
- Uncover errors in your implementation of insertion
- Test insertion in isolation
- Cover likely cases
- Be relatively few and relatively simple
- Give specific priority values, e.g., priority = 5 or 42
- Use only valid queue states and valid nodes (for this exam question)
Your test cases should not
- Duplicate each other
- Worry about cases for which we expect an error (for this exam).
Each of your test cases must include:
- Goal: Description of what this test is designed to test
- State of the Priority Queue at the beginning of the test
- One node to be inserted
- State of the Priority Queue after the test
For example, each or your test cases should follow this pattern, including pictures/sketches for points 2, 3, and 4:
Test 0:|
1. Goal: Insert into an empty Priority Queue
| |
2. Start state: Empty queue:

| |
3. Insert node:
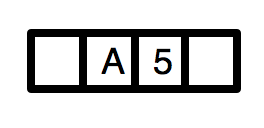
| |
4. End state: Queue contains node:
|
My classification of your tests: Did you have
- IE: Into empty
- LT: Lower than one at tail
- HH: Higher than one at head
- EH: Equal to one at head
- EM: Equal to one in middle
- ET: Equal to one at tail
- IG: Into a gap
This list is exhaustive; there are no other classes of valid insertions. It is a critical testing skill to develop a complete set of equivalence classes and then design s small set of test cases representing each equivalence class.
I characterized each of your tests into one of these seven categories to see if you missed any. That is, beside each of your tests, you should find circled("HH"), for example, if I think that tests inserts a node with a priority higher than the priority of the node pointed to by Head.
While you may have one test that satifies several categories (e.g., Test 3 below), you should have one test for each in isolation (e.g., Tests 6, 8, and 10 below).
Since there are seven classifications of tests, and I gave you one, some duplication was allowed, and you were penalized (-3 points) if you missed a classification. You were penalized (-3 points) if the only tests you had for EH, EM, and ET were the same test. You should have three disjoint tests.
Your test cases might include:
- IE - Insert into an empty queue - Already given
- LT - One node in queue. Insert lower priority.
- EM, EH, ET - One node in queue. Insert same priority.
- HH - One node in queue. Insert higher priority.
- LT - Several nodes in queue, P = 8, 5, 5, 3. Insert lower priority, e.g., 2. Really same as Test 1.
- ET - Several nodes in queue, P = 8, 5, 5, 3. Insert lowest priority, 3.
- IG - Several nodes in queue, P = 8, 5, 5, 3. Insert inner priority, 4.
- EM - Several nodes in queue, P = 8, 5, 5, 3. Insert middle priority, 5. Really same as Test 3.
- IG - Several nodes in queue, P = 8, 5, 5, 3. Insert upper gap priority, e.g., 6. Really same as Test 7.
- EH - Several nodes in queue, P = 8, 5, 5, 3. Insert highest priority, 8.
- HH - Several nodes in queue, P = 8, 5, 5, 3. Insert higher priority, e.g., 10. Really same as Test 4.
To test proper queue insertion, you never need to start with a queue containing more than three nodes. Of course, a test of maximum queue size requires more.
We often include a question on the exam intended to reward students who have started working on the current lab project.
For your lab project, you may want to include more aggressive tests, especially error conditions.
Test-Driven Development was popularized by Kent Beck's book by that name, www.amazon.com/Test-Driven-Development-Kent-Beck/dp/0321146530. By writing tests before we write code, we discover specifications, leading to stronger code and a set of examples of its use. Highly recommended.
Problem 3. AppDev: Processes vs. Threads
You are the architect for a Monitor and Display System, MDS. MDS should gather a large volume of data from N = 128 distinct but similar sources, perform time-consuming analysis on each, and return M = 8 values to be displayed or used for additional analysis, conceptually:
for (i = 1; i ≤ N; i++) {
r[i] = LotsOfWork(dataSet[i]);
}
The application does not matter here; you might be monitoring vital signs from 128 patients, doing predictive failure analysis for 128 shop floor robots, or training 128 neural networks to forecast natural gas demand.
Each LotsOfWork(); takes about one minute of CPU time on a dedicated desktop computer.
Mary, the client for MDS, says, "OK. I'll buy a 16 core (each with a large cache), 64 GB memory machine (about $3-4,000), provided you can convince me you can put those 16 cores to work effectively."
Problem: Convince Mary you can put 16 cores to work effectively for this system.
Hints:
- In Operating Systems, you learned that both processes and threads can be scheduled independently across available cores. Will you use processes or threads? (5 points) Why? (20 points)
- Your answer should demonstrate that you understand how multiple processes and multiple threads work together in such a multi-core with large cache machine.
- "Large cache" means that in addition to the 64 GB of main memory hardware-shared among the 16 cores, each core has its own local (not shared) cache memory. By "large," you should interpret that all code and data for one instance of LotsOfWork(), once loaded, can be executed from cache with no further reading or writing to main memory.
This is a dilemma faced by even developers of app for your phone.
The question is really asking, "Processes or threads? Why? How should they be organized?"
There are good architectures using processes, and there are good architectures using threads, so neither is right, and neither is wrong. Your justification is what matters.
The book and I are intentionally vague about details of processes vs. threads because the details differ substantially from one operating system implementation to another. You must make clear how you are using each of those terms.
Whether you propose processes or threads (or both), tell how many, how they will be allocated across cores, and how the work will be allocated among your processes or threads. "I will use threads becasue my OS book says they share code," will not convince Mary to spend her money.
In concept, both processes and threads can run on separate cores and are scheduled independently, but threads can share code and some data more easily, resulting in a smaller memory footprint and lower system overhead.
You might consider the book's distinction of kernel threads vs. user threads, but Mary is suggesting MDS run on its own dedicated machine, so if we use threads, whether they are scheduled as kernel threads or as user threads will make almost no difference in practice.
The book's characterization of processes as "heavy" and threads as "light" refers to the operating system overhead of creating, managing, and termanating them, not to the quantity or quality of wrok each can do. It is not appropriate to say, "LotsOfWork(); is a heavy-duty work load, so we have to use processes.
Clearly, we want 8 = 128 / 16 instances of LotsOfWork() to run on each core. MDS is "embarrassingly parallel," and we should see nearly 16 x improvement in speed, provided we are smart. Each unit of work probably waits for its data, so separating each unit of work as its own process or thread is likely to exceed the usual 16 x speed-up limit.
There are complications of running on multiple cores. Sharing (by processes or by threads) running on separate cores is more complicated. So is scheduling across multiple cores.
Since each instance of LotsOfWork() should run the same code (on different data), I am tempted to use threads, so copies of the code can be shared. However, even if I use threads, each core will cache the code for LotsOfWork() in its own local cache. Threads on each core sounds like a good solution, but threads across multiple cores must behave more like processes, even if we call them threads.
I think I'll adopt a hybrid architecture: 16 processes (parent and 15 children), one for each core. Hopefully, the OS should be able to balance 16 processes on 16 cores. I am not as confident of the ability of the OS to balance 128 threads evenly across 16 cores.
Each of my 16 processes is responsible for 8 instances of LotsOfWork(). If LotsOfWork() were only CPU-intensive, I'd prefer a sequential loop (for (i = 1; i ≤ 8; i++) LotsOfWork();) for simplicity. However, LotsOfWork() must get its data from somewhere, either from sensors, from disk, or from a Producer() process, so there probably are substantial delays. It will be good if one instance of LotsOfWork() can be computing while another is waiting for its data.
Hence, each of my 16 processes will have 8 threads. Each of the 8 threads shares code to reduce memory footprint on its core. Since the instances running on separate cores are separate processes, there is no attempt to share code across cores, because it will have to be cached anyway.
There is no reason to consider a process or a thread pool.
In summary, my architecture consists of 16 processes, one per core. Each process has 8 threads running on the same core, for less overhead in context swapping and a smaller memory footprint.
Your solution may be quite different from mine.
I intended the eight return values to be a red herring (irrelevant), but several students interpreted that each return values was a separate analysis, in which case assigning a thread to each makes sense. One student suggested a separate process for each of the eight return values and separate threads for each of the 128 units of work, but that misses that for one of the 128 units of work, the same data is used for each of the return values, so putting them in separate processes leads to additional inter-process communication.
At least, you should address the effects of
- Scheduling?
- Sharing, e.g., code?
- Memory?
- Cache?
- Expected speed-up?
Speed-up? I suspect Mary wants assurances the work will finish much faster. How much faster will your parallelized program be? Conventional wisdon says the best you can hope for from 16 cores is 16 x as fast. However, if each unit of work spends much time waiting for its data, we should be much faster than 16 x by doing the analysis for one unit of work while anotherone is waiting for its data.
This is intended as a challenging exam question to separate the A students from the B students. I will grade with mercy.
Problem 4 Semaphores and Mutual Exclusion
Semaphore S is an integer variable, accessed only through two atomic hardware operations defined as if
SHARED:
int S; |
| |
wait(S) { /* "P" - proberen */
while (S <= 0) ; /* wait */
S --;
} |
signal(S) { /* "V" - verhogen */
S ++;
} |
Suppose we have two cooperating processes sharing Semaphore S, with initial value 1:
SHARED:
Semaphore S = 1; |
14:
15:
16:
17:
18:
19: |
Process 0:
. . .
while (TRUE) {
signal(S);
/* CRITICAL SECTION */
wait(S);
/* REMAINDER SECTION */
} |
Process 1:
. . .
while (TRUE) {
signal(S);
/* CRITICAL SECTION */
wait(S);
/* REMAINDER SECTION */
} |
- [5 points] What does "mutual exclusion" mean in this example?
- [20 points] Explain how the semaphore enforces mutual exclusion. Use a careful stepping through the pseudo-code to make your case.
Repeated from last year's exam to reward students for looking over exams from previous years.
Do not be confused by one processor vs. several. What matters is that they share one semaphore.
- [p. 206] If one process P1 is executing in its critical section (line 16:), no other processes can be executing in their critical sections. Semaphores are one way mutual exclusion can be enforced, but semaphores are not the only means.
- To show mutual exclusion is enforced requires thorough analysis (which does not hold here). To show mutual exclusion is not enforced only requires one example of a scenario for which it fails. It is similar in mathematics: To show a statement is true, you must prove it; to show the statement is false, you need only give one counter-example.
This code does not enforce mutual exclusion, as the following example shows. Yes, there are sequences that execute correctly, but the fact that one possible incorrect sequence exists demonstrates that mutual exclusion is not enforced.
Fundamental: We can make no assumptions about the order or the relative speed of processes executing in parallel. Suppose we have the following sequence of events:
Process 0:
. . .
while (TRUE) {
signal(S); // S++ -> 2
/* CRITICAL SECTION */
INTERRUPT ...
|
Process 1:
while (TRUE) {
signal(S); // S++ -> 3
/* CRITICAL SECTION */
// TWO processes are in their critical
// sections at the same time.
// Mutual exclusion has FAILED
|
A key insight in these mutual exclusion discussions is to see when is the worst time for an interrupt to occur.
Compared to the code I showed in class for the semaphore example, wait(S) and signal(S) are reversed.
Scoring: If you recognized it does not work, but had little idea what is wrong, you received about 8 of the 20 points for part b. If you said it does work, and you gave a reasonable argument (although wrong), you might have received up to 10 of the 20 points.
The question says, "Use a careful stepping through the pseudo-code to make your case." If you did not do that, but gave the answer you saw on last year's exam, you were penalized (-5 points). A "a careful stepping through the pseudo-code" is not satisfied by an English paragraph.
You did not have to recognize what is wrong (signal() and wait() are reversed) to receive full credit.
This is not a producer-consumer example.
I did not grade this question with mercy. As someone said on one of the cards, "We beat this to death."
Problem 5. Fork BOMB -- Many fork()s
What happens when this program is executed?
#include <stdio.h>
#include <unistd.h>
int main(void) {
printf("PID: %d\n", getpid());
fork();
main();
}
Hints:
- This programs compiles and runs, at least on my laptop.
- By "what happens?", you should address both what I might see on my screen and what might be going on inside my processor and memory.
- The answer is not, "It crashes." It doesn't, at least on my laptop.
- You cannot be expected to guess what values are printed.
- I expect a reasoned outline of a likely sequence of events.
- Since there is a call to fork(), your explanation might talk about parent and children processes.
- A drawing or a cartoon (or two) may be helpful.
- Your answer should show me that you understand fork() and likely operating system memory management and book-keeping.
Points you might make include:
- Fork(): Each time fork() is called, it created a new child process with an exact copy of its parent's memory image, except with a different PID.
- Main(): This is a recursive call. Yes, you can call main() recursively.
- Each call to main() prints its process ID and creates a new child process. Then both parent and child process call main() recursively.
- Each parent process goes merrily on its way. It does not wait for its child to finish.
- Each child process executes the code with which it was born. There is no exec() to invoke a different program.
- Logically, no process ever finishes. There is no recursion termination.
- For each process, the OS must allocate space for a Process Control Block, probably less than 100 words, and the OS must allocate memory for the process itself, probably a few Kb. Hence 4 GB might accommodate roughly 106 ~ 220 processes.
- The speed of this program's execution is limited by how fast we can write to the screen, probably less than a hundred lines (processes spawned) per second. That is probably several times slower than the system clock is interrupting my processes.
- With all those points being made, the logical call graph is a perfect binary tree, say with the left child node representing the parent process and the right child node representing the child process. At recursion level n, we have 2n processes. At 3 levels of recursion:
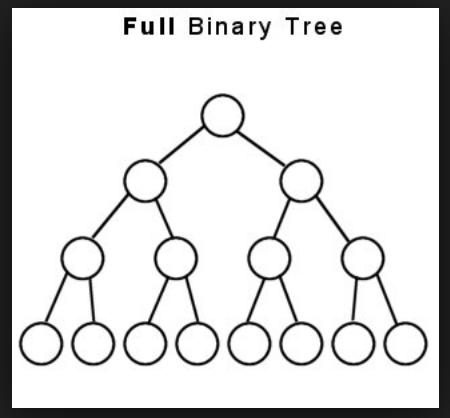
- In practice, when fork() creates a child process, the scheduler probably lets the parent process continue running for a while, so if left children nodes represent parent processes, a snapshot of the call structure probably has much longer left chains than right chains.
- Whatever the details, the memory in my computer, both physical and virtual is finite, so the program cannot run indefinitely as described.
- So, how does it fail? Speculation is what I asked for. If the OS is well-written, when there is not enough memory, fork() should fail to create a child, and it should return -1 to the parent. The parent does not check, so it calls main() again, but there is no child doing the same thing. If there are no interrupts, we should expect to see the same PID printed repeatedly because we are still in the parent process. Of course, before we exhaust memory, we may have a million or so processes all running in that mode, so the number printed should change with each interrupt.
- Infinite recursion
Exhausts memory
Fork() fails to create new child process
Recuresion continues, but no more children
Machine becomes sluggish
Operator kills all processes running in that window
- -10 if you saw only infinite recursion. Each process requires memory, and memory is finite.
- -20 if you did not recognize recursion.
- -7 if no speculation on the mode of failure
From one student's exam paper:

| |