| |
Your second midterm examination will appear here. It covers Chapters 6 -- 10.
It will be a 50 minute, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Questions will be similar to homework questions from the book. You will
be given a choice of questions.
I try to ask questions I think you might hear in a job interview. "I
see you took a class on Operating Systems. What can you tell me about ...?"
See also Dr. Barnard's notes.
He was using a different edition of our text, so chapter and section numbers
do not match, but his chapter summaries are excellent.
Results on exam 1 suggest you may wish to maintain a vocabulary list.
Directions:
Read and follow the directions.
- Write on four of the five questions. If you write more than four questions, only the first four will be graded. You do not get extra credit for doing extra problems.
- Read the entire exam. If there is anything you do not understand about a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly what interpretation of the question you intend to answer.
- In the event this exam is interrupted (e.g., fire alarm or bomb threat), students will leave their papers on their desks and evacuate as instructed. The exam will not resume. Papers will be graded based on their current state.
- Begin your answer to each question at the top of a fresh sheet of paper [or -5].
- Be sure your name is on each sheet of paper you hand in [or -5]. That is because I often separate your papers by problem number for grading and re-assemble to record and return.
- Write only on one side of a sheet [or -5]. That is because I scan your exam papers, and the backs do not get scanned.
- Be sure I can read what you write.
- If I ask questions with parts
- . . .
- . . .
your answer should show parts
- . . .
- . . .
Score Distribution:
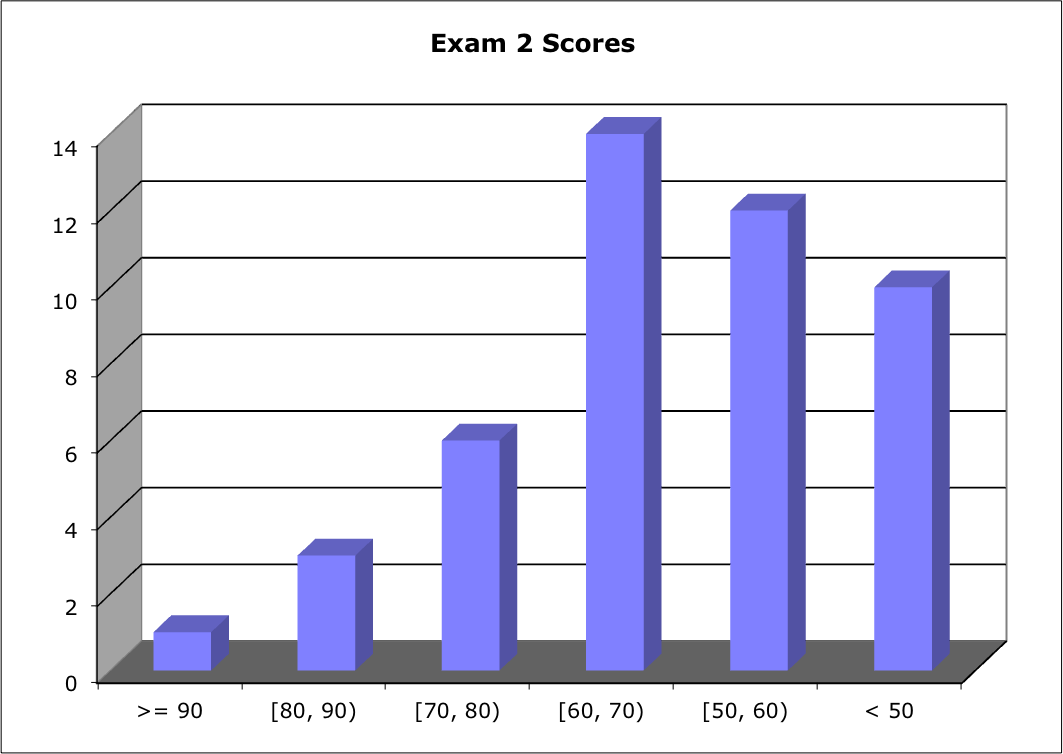
Range: 29 - 92; Median: 50.0; Mean: 60.0; Standard Deviation: 18.0
These shaded block are intended to suggest solutions; they are not intended to be complete solutions.
Jump to question
Problem 1 Definitions
Problem 2 Deadlock
Problem 3 Process Synchronization
Problem 4 Paging with Protection
Problem 5 Tricky C
Problem 1 Definitions
Give careful definitions for each term (in the context of computer operating systems):
- Preemptive scheduling
- Round-robin scheduling
- Atomic instruction
- Readers-writers problem
- Resource allocation graph
- Address binding
- Demand paging
- Sequential file access
- Direct file access
- File-System mounting
Make-up:
- Processor affinity
- Load balancing
- Priority inversion
- Monitor for mutual exclusion
- Logical address space
- Physical address space
- Demand paging
- External fragmentation
- Working set
- File-System mounting
Hint: A definition is 1 - 2 sentences.
Warning: A definition that starts "Z is when ...," or "Z is where ..." earns -5 points.
Most of these terms are headings of subsections in our text.
Each part is worth 2 points, so you received 5 "free" points.
- Preemptive scheduling (5.1.3).
In non-preemptive scheduling, CPU-scheduling, a process keeps the CPU until the process releases the CPU by terminating or by switching to a waiting state. In preemptive scheduling, the CPU can be taken away, most commonly in response to a timer interrupt. Preemptive scheduling concerns one resource, the CPU.
- Round-robin scheduling (5.3.4) is a preemptive schedule algorithms in which the Ready List is treated as a FIFO queue. Your answer needed to mention both the order in which processes are scheduled (FIFO) and preemption.
- Atomic instruction (p. 232) - as one uninterruptable unit.
- Readers-writers problem (6.6.2) is one of the classical problems of synchronization. Multiple reading processes and multiple writing processes need to share access to a single shared data resource.
- Resource allocation graph (7.2.2) is a graphical representation of processes i) requesting and ii) holding resources.
- Address binding (8.1.2) is the tying of a virtual address to a physical address. When do we know the physical address of a particular line of code of variable? Addresses can be bound at language design time, at language implementation time, at compile time, at load time, or during execution. Virtual memory is a technique for binding addresses during execution.
- Demand paging (9.2). Pages of virtual memory are loaded into physical memory only as they are needed.
- Sequential file access (10.2.1) processes information in the file strictly in order.
- Direct file access (10.2.2) can access records in a file in no particular order. "File access" concerns access to information within a file, not to a list of files. That would be accessing a directory. "File access" does not depend on all or a part of the file being in memory
- File-System mounting (10.4). The operating system places a file system (typically a disk or equivalent) at a specified location within the file system. For example, Windows mounts drives as letters in the MyComputer "folder." Did you ever wonder what Windows would do if you tried to mount more than 26 drives?
Make-up:
- Processor affinity
- Load balancing - Processor affinity vs. load balancing. Both concern multi-processor scheduling. See pp. 202 - 204. Processor affinity suggests a process should remain on the same processor to exploit caching. Load balancing suggests a process should be moved from an overloaded processor to a lightly loaded processor.
- Priority inversion (6.5.4)
- Monitor for mutual exclusion - See Section 6.7 vs. 6.5. Both are means to enforce mutual exclusion. "The monitor construct ensures that only one process at a time can be active within the monitor." In Java, the keyword synchronized enforces a monitor-like discipline. Counting or binary semaphores provide mutual exclusion through indivisible operations wait() and signal().)
- Logical address space
- Physical address space (Sect. 8.1.3)
- Demand paging (9.2)
- External fragmentation (Problem 8.9, p. 351) - Internal vs. external fragmentation. See p. 287. Both are wasted memory. Internal fragmentation is within a page, segment, partition, or disk block. External fragmentation is memory that is free, but it is in such small units that it cannot be allocated effectively. It is wasted memory outside a segment, partition, or disk block. Paging avoids external fragmentation.
- Working set (in the context of memory management)
- File-System mounting (10.4)
Problem 2 Deadlock
- Consider a system consisting of four interchangeable resources (R1, R2, R3, and R4) of the same type that are shared by three processes (P1, P2, and P3). Each process requires at most two of the resources. Prove that the system is deadlock free.
- Consider a system with m resources of the same type that are shared
by n processes. Resources can be requested and released by processes
only one at a time. Assume the maximum need of each process is between 1
and m resources, and that the sum of all maximum needs is less than m
+ n. Show that the system is deadlock-free.
Warning: An example is not a proof.
Problems 7.15 and 7.16, p. 309.
This is a logic test. An example is not a proof. It is not enough to say, "Suppose P1 holds ..."
- The only way you can prove no deadlock can occur is to demonstrate that one of the four necessary conditions
- Mutual exclusion,
- Hold and wait,
- No preemption, and
- Circular wait,
cannot occur. The first three can occur, so your only hope is to prove NO CIRCULAR WAIT.
Several students asserted there is no hold and wait. That is false. In the scenario described, if a process holds one resource, requests another, and that request cannot be granted, the requesting process holds what it has and waits for what it has requested. Yes, the wait cannot be infinite, but it is a wait, nonetheless.
The proof is by contradiction. Suppose there is a circular wait. Then each process holds some resources it needs and requests others. Since each process needs at most two resources, it must be the case that each process holds one, requests another one, and must wait. But that accounts for only 3 of the 4 resources, so one more resource is available. That remaining resource can me given to any one of the three waiting processes. That process no longer is waiting. That contradicts the assumption of a circular wait.
Hence, there can be no circular wait. Hence, there can be no deadlock.
The logical power of a proof by contradiction is greater than a closely related argument: If each process holds one resource, you can give the remaining resource to one process. It can finish, and then the other two processes can finish using the two released resources. That is a good example, but it only proves that that scenario does not deadlock. It does not prove there could not be a deadlock some other way. Of course, there can't, but you have not proven it.
Alternatively, you can enumerate all the possible cases:
If any process holds two, it can finish, releasing its resources for
others to use.
Worst case, if all three hold one, there is one left. the first one to
request its second can be granted its request, finish, release its resources,
and allow the other two to finish in parallel.
If a process holds none, there are enough resources for the other two to
receive there full requests and complete.
Hence, there can be no circular wait.
- Let R[i] denote the request of process i.
We know 1 <= R[i] <= m.
We know Sumi R[i] < m + n.
If any process holds its full request R[i], it can finish and release
what it holds.
The worst case is when each process holds all but one of its requests, R[i]
- 1, and one of them asks for another. In that case, the number of
resources being held is
Sumi (R[i] - 1) = Sumi (R[i])
- n < m + n - n = m.
That is, the number of resources held is less than m, the total
available. Hence, at least one request can be granted, the requesting process
can finish and release its resources for the benefit of the others.
-5 if you appeared to assume one process requests one resource. Each process can request up to m resources.
For the record, my "solution" assumes that if a process is granted the resources it requests, it will finish and release its resources. That is the standard OS assumption, and the assumption I assumed you should make. However, it is false for many OS and real-time application processes.
Problem 3 Process Synchronization - Critical-Section Problem with TestAndSet
Background:
Suppose we have an atomic operation TestAndSet(), which works as if it were implemented by pseudocode such as (Figure 6.4 from our text)
boolean TestAndSet(boolean *target) {
boolean rv = *target;
*target = TRUE;
return rv;
}
The function BoundedWaitingMutualExclusion (pseudocode adapted from Figure 6.8 from our text) claims to solve the critical-section problem:
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15: | |
void BoundedWaitingMutualExclusion(int i, int j, int n) {
boolean key;
while (TRUE) {
waiting[i] = TRUE;
key = TRUE;
while (waiting[i] && key) { key = TestAndSet(&lock); }
waiting[i] = FALSE;
{
// CRITICAL SECTION - ASSUME INTERRUPT
}
j = (i + 1) % n;
while ( (j != i) && !waiting[j] ) { j = (j + 1) % n; }
if (j == i) { lock = FALSE; }
else {waiting[j] = FALSE; }
{
// REMAINDER SECTION
}
}
} |
We have two processes which share memory. Each calls BoundedWaitingMutualExclusion():
| Process Alice | | Process Bob |
|---|
Memory region shared by both processes: #define N 2
boolean waiting[N]; // Assume initialized all FALSE
boolean lock = FALSE; |
|
1:
2:
3: | |
#define ME 0
int j = 0;
BoundedWaitingMutualExclusion(ME, j, N);
| | 1:
2:
3: | |
#define ME 1
int j = 1;
BoundedWaitingMutualExclusion(ME, j, N); |
Questions:
- A solution to the critical-section problem must satisfy what requirements? List them.
- At BoundedWaitingMutualExclusion() line 6, what is the purpose of the while(...) loop?
- At BoundedWaitingMutualExclusion() line 10, what is the purpose of the while(...) loop?
- Assuming Process Alice runs first, step carefully through the execution until each process has completed one pass through its critical section. Show values at each step for all local and all shared variables. Assume a context swap occur in the middle of the CRITICAL SECTION and that any busy waiting eventually is interrupted for a context swap.
Hint: The answer to part d) might have the form:
| Process Alice | Shared | Process Bob |
|---|
| Code line | i | j | key |
waiting | lock |
Code line | i | j | key |
| A 2: | | 0 | |
[F, F] | F |
| | | |
| BWME(0, 0, 2) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 3: (T) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 4: | 0 | 0 | |
[T, F] | F |
| | | |
| | | | |
| |
| | | |
| BWME(0, 0, 2)BWME(0, 0, | 0 | 0 | 0 |
| |
BWME(0, 0, 2)BWME(0, 0, | 0 | 0 | 0 |
- (5 points) See page 228 or 230. We must show that
- Mutual exclusion is preserved;
- The progress requirement is satisfied; and
- The bounded waiting requirement is met.
"No busy waiting" is NOT a requirement. Busy waiting is a concern for performance, not for correct functioning.
- (3 points) Wait until no other process is in its critical section AND it is this process's turn among those waiting. Enforces Mutual Exclusion and Bounded Waiting.
- (3 points) Cycle through waiting processes. The loop cycles through non-waiting processes, stopping at a waiting process. The result is to set the index to the next waiting process. The purpose is to prevent the same process from re-entering its critical section repeatedly, starving an unlucky process is waiting, but never gets the CPU when the way is clear. Enforces Bounded Waiting.
- (14 points) Details of your answer depend on when you let context swaps occur. See the discussion on pages 233 - 234. In grading, I was more concerned with whether you followed what the code does than with whether you interrupted exactly when I intended. If you interrupted Process Alice during her CRITICAL SECTION and then ran Process Bob until he encountered a busy wait, you were more likely to discover what the loop at line 10 is doing.
See this simulation app that lets you step through this code.
One scenario is:
| Process Alice | Shared | Process Bob |
|---|
| Code line | i | j | key |
waiting | lock |
Code line | i | j | key |
| A 2: | | 0 | |
[F, F] | F |
| | | |
| BWME(0, 0, 2) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 3: (T) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 4: | 0 | 0 | |
[T, F] | F |
| | | |
| BWME 5: | 0 | 0 | T |
[T, F] | F |
| | | |
| BWME 6: (T & T) => T | 0 | 0 | F |
[T, F] | T |
Note: Line 6 is executed twice | | | |
| BWME 6: (T & F) = > F | 0 | 0 | F |
[T, F] | T |
| | | |
| BWME 7: | 0 | 0 | F |
[F, F] | T |
| | | |
| BWME 8: CRITICAL | 0 | 0 | F |
[F, F] | T |
| | | |
| context swap |
| | | | |
[F, F] | T |
B 2: | | 0 | |
| | | | |
[F, F] | T |
BWME(1, 0, 2) | 1 | 0 | |
| | | | |
[F, F] | T |
BWME 3: (T) | 1 | 0 | |
| | | | |
[F, T] | T |
BWME 4: | 1 | 0 | |
| | | | |
[F, T] | T |
BWME 5: | 1 | 0 | T |
| | | | |
[F, T] | T |
BWME 6: (T & T) => T | 1 | 0 | T |
| | | | |
[F, T] | T |
BWME 6: (T & T) => T | BUSY WAIT until |
| context swap |
| BWME 8: CRITICAL | 0 | 0 | F |
[F, T] | T |
| | | |
| BWME 9: | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 10: (T & F) => F | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 11: (F) | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 12: | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 13: REMAINDER | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 3: (T) | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 4: | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 5: | 0 | 1 | T |
[T, F] | T |
| | | |
| BWME 6: (T & T) => T | 0 | 1 | T |
[T, F] | T |
| | | |
| BWME 6: (T & T) => T | Forced to take turns
BUSY WAIT until |
[T, F] | T |
| | | |
| context swap |
| | | | |
[T, F] | T |
BWME 6: (F & T) => F | 1 | 0 | T |
| | | | |
[T, F] | T |
BWME 7: | 1 | 0 | T |
| | | | |
[T, F] | T |
BWME 8: CRITICAL | 1 | 0 | T |
| context swap |
| BWME 6: (T & T) => T | Forced to take turns
BUSY WAIT until |
[T, F] | T |
| | | |
| context swap |
| Your solution could end here after 1 complete CRITICAL SECTION in each process | |
[T, F] | T |
BWME 9: | 1 | 1 | T |
| | | | |
[T, F] | T |
BWME 10: (F & T) => F | 1 | 1 | T |
| | | | |
[T, F] | F |
BWME 11: (T) | 1 | 1 | T |
| | | | |
[T, F] | F |
BWME 13: REMAINDER | 1 | 1 | T |
| context swap |
| BWME 6: (T & T) => T | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 6: (T & F) => F | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 7: | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 8: CRITICAL | 0 | 1 | F |
[F, F] | T |
| | | |
| etc. |
Problem 4 Paging with Protection
- In a paging implementation of virtual memory, describe how memory protection can be accomplished. Discuss how to prevent a process from accessing memory not belonging to it.
- What changes would be necessary to allow two processes to share access to a page?
- How does your answer change for a segmentation implementation of virtual memory?
Hint: Your answer should provide enough detail to guide an implementor.
Distinguish per-process page tables from system-wide page tables.
- (10 points) See Section 8.4.3. A process should be able to access only "its" pages. A per-process page table accomplishes that. A process physically has no means to access pages not in its virtual address space. If a page IS in the virtual address space of a process, we should assume that process can access that page, and there is no need for an additional guard bit.
If the OS uses a system-wide page table, it needs a process ID field in the page table anyway to indicate which pages belong to which processes. The hardware merging the page frame number with the page offset in the lower order address bits makes it impossible that a valid page address addresses a location outside the corresponding page frame. There is no need to check the page offset portion of the address.
Several students suggested "There is a bit to say whether the process has access." That is not needed in a per-process page table. In a system-wide page table, the bit you suggest would need to be indexed by process ID. Good idea in principle, but it does not work in practice. [-4 points]
Several students suggested using mutual exclusion primitives to enforce access only by the owning process. Problem 1) That requires that the other programmer obey the rules, not a particularly strong protection. Problem 2) The fastest implementations of mutual exclusion require several clock cycles, and virtual memory must provide memory access at a rate of about 1.2 - 1.3 memory accesses per clock cycles. Good idea in principle, but it does not work in practice. [-4 points]
- (8 points) See Section 8.4.4. For per-process page tables, the shared pages must be in the page table of each sharing process. For a system-wide page table, we do not want a dynamic data structure of process IDs, so we put the page into the page table multiple times.
Make copies? If access is read-only, that could work, but it would be inefficient.
Do you need mutual exclusion? Probably, but mutual exclusion is not a property of virtual memory. The memory subsystems would say, "You want to share these pages? Fine. Don't hurt yourself."
You might observe that the entire raison d'être' of threads is to be able to share access to memory. [+4 points]
- (7 points) A page offset cannot reference memory outside its own page, but segment offsets can, because most segments have a length less than the maximum segment size. Checking the validity of page numbers is enough for pages, but for segments, we also must check the validity of the segment offset.
A segment belongs to one (or more) processes. Checking the validity of segment numbers owned by a process is done in the same manner as checking page numbers. Since segments can have different sizes, the hardware cannot enforce so easily checking access beyond the segment boundary. Hence, the segment table includes a length field, and the offset is compared against it.
"Segment fault" may be either an attempt to access a segment that did not belong to you or to access one of your segments with an offset that is greater than the segment length.
Virtual memory does not (directly) concern files. An answer in terms of file protections does not answer the question asked.
Problem 5 Tricky C
Here is a tricky C program:
#include <stdlib.h>
#include <stdio.h>
#define MAX 127
int i = 23456;
int getNumber(void)
{
printf ("In getNumber, i = %d\n", i);
return ++i;
}
void main(int argc, char** argv)
{
int *array;
int index = 0;
int current = 0;
int j = 0;
while ( EOF != (current = getNumber()) ) /* EOF has the value -1 */
{
printf ("In while, index, current = %d, %d\n", index, current);
if (! index) { array = (int *)malloc(MAX); }
array[index++] = current;
index &= MAX;
}
for (; j < index; j++)
{
printf("%10d: %10d\n", j, array[j]);
}
}
I assure you it compiles and runs.
What does it print? Explain.
Exact results depend on non-standard behaviors of your compiler. When I run it with a particular compiler, I get
In getNumber, i = 23456
In while, index, current = 0, 23457
In getNumber, i = 23457
In while, index, current = 1, 23458
. . .
In getNumber, i = 23583
In while, index, current = 127, 23584
In getNumber, i = 23584
In while, index, current = 0, 23585
*** [a] Error -1073741819
Dr. Brylow writes: This program looks like it should read and store an arbitrary list of numbers, but
it has three major problems:
- the malloc size is only one fourth of what is intended,
- the return value from malloc() is not checked against NULL, and most importantly,
- each successive dynamically allocated block is lost because the pointers aren't being stored anywhere else.
- Also, it is just badly written, with the last line depending on a fragile property of the MAX constant being one less than a power of 2.
Having a macro named "EOF" does not imply there is a file anywhere. That is bad, confusing programming practice. It violates the Principle of Least Astonishment, but it runs, and you will see worse in the wild.
I gave full credit if you recognized at least two of Dr. Brylow's 3 (++) problems.
Counters might overflow? Try it. What happens?
| |