| |
Your second midterm examination will appear here. It covers Chapters 5 - 12.
It will be a 50 minute, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Section and page number references in old exams refer to the edition of the text in use when that exam was given. You may have to do a little looking to map to the edition currently in use. Also, which chapters were covered on each exam varies a little from year to year.
Questions may be similar to homework questions from the book. You will
be given a choice of questions.
I try to ask questions I think you might hear in a job interview. "I
see you took a class on Operating Systems. What can you tell me about ...?"
Preparation hints:
Read the assigned chapters in the text. Chapter summaries are especially helpful. Chapters 1 and 2 include excellent summaries of each of the later chapters.
Read and consider Practice Exercises and Exercises at the end of each chapter.
Review authors' slides and study guides from the textbook web site
Review previous exams listed above.
See also Dr. Barnard's notes. He was using a different edition of our text, so chapter and section numbers do not match, but his chapter summaries are excellent.
Results on exam 1 suggest you may wish to maintain a vocabulary list.
Read and follow the directions:
- Write on four of the five questions. If you write more than four questions, only the first four will be graded. You do not get extra credit for doing extra problems.
- In the event this exam is interrupted (e.g., fire alarm or bomb threat), students will leave their papers on their desks and evacuate as instructed. The exam will not resume. Papers will be graded based on their current state.
- Read the entire exam. If there is anything you do not understand about a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of paper [or -5].
- Be sure your name is on each sheet of paper you hand in [or -5]. That is because I often separate your papers by problem number for grading and re-assemble to record and return.
- Write only on one side of a sheet [or -5]. That is because I scan your exam papers, and the backs do not get scanned.
- No electronic devices of any kind are permitted.
- Be sure I can read what you write.
- If I ask questions with parts
- . . .
- . . .
your answer should show parts
- . . .
- . . .
- Someone should have explained to you several years ago that "X is when ..." or "Y is where ..." are not suitable definitions (possibly excepting the cases in which X is a time or Y is a location). On Exam 2, "X is when ..." or "Y is where ..." earn -5 points.
The university suggests exam rules:
- Silence all electronics (including cell phones, watches, and tablets) and place in your backpack.
- No electronic devices of any kind are permitted.
- No hoods, hats, or earbuds allowed.
- Be sure to visit the rest room prior to the exam.
On exam 1, we had an instance of at least one student using a prohibited aid, so for exam 2, you will put all bags, coats, electronics, purses, bulky hoodies, and anything else we judge capable of concealing a prohibited aid across the front of the classroom when you enter. Sorry, but collectively, you earned this level of intrusion. I assume you have worked hard to prepare for this exam; you should not need to compete with students who cheat.
In addition, you will be asked to sign the honor pledge at the top of the exam:
"I recognize the importance of personal integrity in all aspects of life and work. I commit myself to truthfulness, honor and responsibility, by which I earn the respect of others. I support the development of good character and commit myself to uphold the highest standards of academic integrity as an important aspect of personal integrity. My commitment obliges me to conduct myself according to the Marquette University Honor Code."
Name ________________________ Date ____________
Score Distribution:
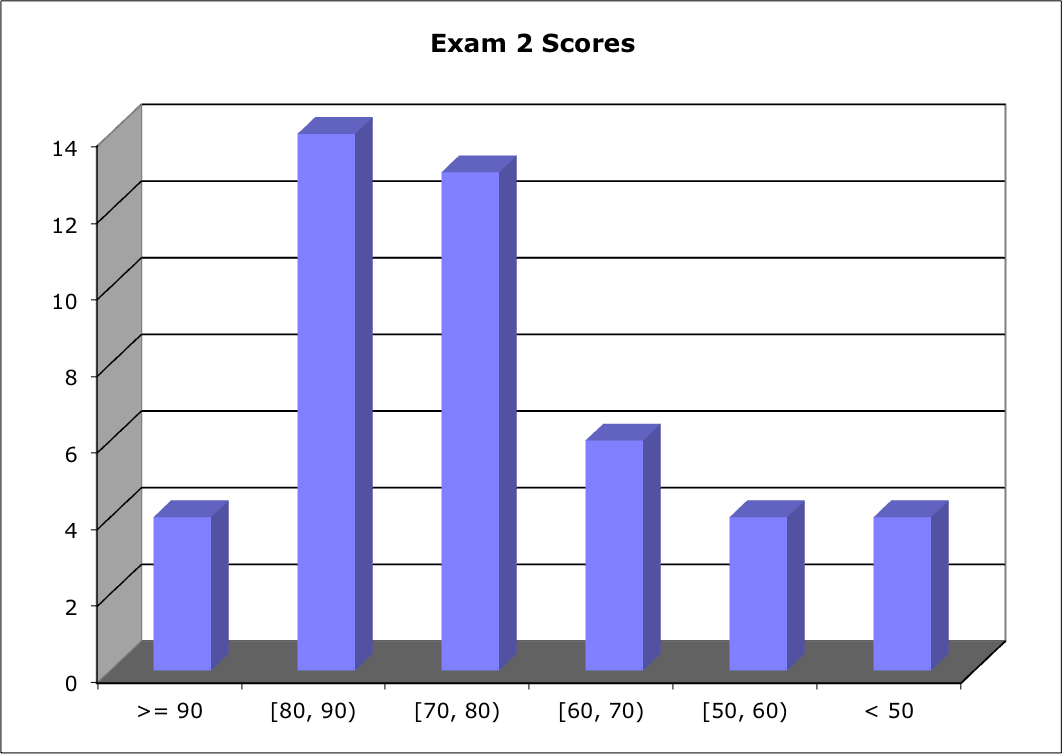
Median: 75; Mean: 73.5; Standard Deviation: 17.0
These shaded blocks are intended to suggest solutions; they are not intended to be complete solutions.
Wednesday:
Problem 1 Definitions
Problem 2 Page Replacement Strategies
Problem 3 Process Synchronization - Critical-Section Problem with TestAndSet
Problem 4 Disk Scheduling Algorithms
Problem 5 Directories and Files
Friday:
Problem 1 Definitions
Problem 2 Process Scheduling Strategies
Problem 3 Process Synchronization - Allocate and Release
Problem 4 Disk Scheduling Algorithms
Problem 5 Directories and Files
Problem 1 Definitions
Give careful definitions for each term (in the context of computer operating systems):
Wednesday:
- Atomic execution of an instruction
- Mutual Exclusion
- Locality
- Page vs. page frame
- Active vs. Working set
- RAID
Friday:
- Cooperating processes
- Starvation
- Active vs. Working set
- Indexed file access
- Semaphore
Specific questions were chosen from this collection:
- Active vs. Working set (in the context of memory management). Both concern memory addresses used by a program. The working set (Section 9.6.2) is the (fuzzy) set of pages the program is "naturally" using at the moment. The active set is the set of pages actually stored in memory at the moment. We hope that the active set contains the working set, more or less. When the working set is significantly larger than the active set, we get thrashing. However, I must cut you some slack, though, because our text makes no mention of the term "active set."
- Address binding (8.1.2) is the tying of a virtual address to a physical address. When do we know the physical address of a particular line of code of variable? Addresses can be bound at language design time, at language implementation time, at compile time, at load time, or during execution. Virtual memory is a technique for binding addresses during execution.
- Atomic execution [p. 210]: An instruction is implemented as one uninterruptable unit.
- Busy waiting [p. 213]. Waiting while holding the CPU, typically waiting by loop, doing nothing. For example
while (TestAndSet(&lock) ; // Does nothing
A process in a Waiting state (in the sense of the Ready-Running-Waiting state diagram) is not busy waiting because it is not holding the CPU.
- Cooperating process [p. 203]: One that can affect or be affected by other processes executing in the system.
- CPU-I/O burst cycle [p. 262]: Processes typically alternate between periods of high CPU activity and periods of high I/O activity
- Critical-Section problem [p. 206] solution must provide mutual exclusion, must allow each process to make progress, and must ensure the time a process must wait to enter its critical section is bounded.
- Deadlock vs. starvation [p. 217]. Both concern indefinite wait. "A set of processes is in a deadlocked state when every process in the set is waiting for an event that can be caused only by another process in the set." Starvation is also an indefinite wait not satisfying the definition of deadlock, often due to an accidental sequence of events.
- Deadlock necessary conditions [p. 318]: Mutual exclusion, Hold and wait, No preemption, Circular wait.
"Wait ON" vs. "Wait FOR." One waits ON superiors, to take care of, or to serve; e.g., a store clerk waits ON customers. One waits FOR peers, e.g., you might wait for a friend to go to the lab. A server process might be said to "wait on" a client process, but process scheduling, mutual exclusion, deadlock, etc., involve processes waiting FOR each other.
- Demand paging (9.2). Pages of virtual memory are loaded into physical memory only as they are needed.
- Error-correcting code [p. 479]: Encoding data is such a way that a certain number of errors can be detected and a (smaller) number of errors can be corrected. (Circular statements such as "Error-correcting codes are codes for correcting errors" received zero points.) Encryption codes protect against unauthorized access.
- File (p. 504). A named collection of related information recorded on secondary storage.
- File access: Sequential vs. direct. Sequential access (11.2.1) processes information in the file strictly in order. Direct access (11.2.2) can access records in a file in no particular order. "File access" concerns access to information within a file, not to a list of files. That would be accessing a directory. "File access" does not depend on all or a part of the file being in memory.
- File-System mounting (11.4). The operating system places a file system (typically a disk or equivalent) at a specified location within the file system. For example, Windows mounts drives as letters in the MyComputer "folder." Did you ever wonder what Windows would do if you tried to mount more than 26 drives?
- Indexed file access, Similar to direct file access, except that an index is used to record pointers to blocks of a file. To find a record in the file, we search the index and use the pointer to access the file directly. Not the same as direct file access.
A different meaning is to store (index) the contents of many files, to that a desired file can be found quickly.
The first meaning is for accessing records of a single file; the second is for accessing many files.
- Internal vs. external fragmentation [p. 363]. Both are wasted memory. Internal fragmentation is within a page, segment, partition, or disk block. External fragmentation is memory that is free, but it is in such small units that it cannot be allocated effectively. It is wasted memory outside a segment, partition, or disk block. Paging avoids external fragmentation.
- Locality [p. 428]. The concept that if a location in memory (or on disk) is referenced, the probability increases that nearby locations will be referenced soon. Locality makes the entire memory hierarchy effective.
- Logical address space vs. Physical address space (Sect. 8.1.3)
- Memory hierarchy Processor registers > cache levels 1, 2, and 3 > main memory > disk cache > local disk storage > LAN storage > remote storage > off-line storage > remote storage. Trade-offs between speed, capacity, volatility, and cost.
- Memory mapped files [p. 430]. Using virtual memory techniques to treat a sequentially accessed file as routine memory access.
- Monitor vs. semaphore (for mutual exclusion). See Section 5.8 vs. 5.6. Both are means to enforce mutual exclusion. "The monitor construct ensures that only one process at a time can be active within the monitor." In Java, the keyword synchronized enforces a monitor-like discipline. Counting or binary semaphores provide mutual exclusion through indivisible operations wait() and signal().
- Mutual exclusion [p. 206] If one process P1 is executing in its critical section, then no other processes can be executing in their critical sections.
- NAS = Network-Attached Storage [p. 471]; SAN = Storage-Area Network [p. 472].
- Page vs. Page frame [p. 366]. A page is a unit of the virtual (apparent) memory of a process. A page frame is a physical location in memory.
- Page fault [p. 403]. CPU attempts to access a memory location on a page that is not found in the page table.
- Page replacement (9.4): FIFO, Optimal, LRU, approximate LRU, Second-chance.
- Preemption - Taking resources away from a process that holds them. Preempting a running process by a timer interrupt is one example, but in principle, the operating system could preempt any resource. Preemption is more than interruption. Preempting a running process takes away the CPU resource, but not necessarily its other resources.
- Preemptive scheduling (6.1.3).
In non-preemptive scheduling, CPU-scheduling, a process keeps the CPU until the process releases the CPU by terminating or by switching to a waiting state. In preemptive scheduling, the CPU can be taken away, most commonly in response to a timer interrupt. Preemptive scheduling concerns one resource, the CPU.
- Priority inversion [p. 217]: A high priority process is forced to wait for a lower priority process to release some resource(s).
- Processor affinity vs. load balancing (6.5.2). Both concern multi-processor scheduling. Processor affinity suggests a process should remain on the same processor to exploit caching. Load balancing suggests a process should be moved from an overloaded processor to a lightly loaded processor.
- Proportional share real-time CPU scheduling [p. 289]: Allocate T shares among all applications. An application can receive N shares of time, ensuring that the application is allocated N/T of the total processor time.
- Race condition [p. 205]: Several processes access and manipulate the same data concurrently, and the outcome depends on what happens to be the order of execution.
- RAID [p. 484]. Redundant arrays of independent/inexpensive disks use to provide data redundancy and rapid access.
- Rate-monotonic real-time CPU scheduling [p. 287]: Upon entering the system, each periodic task is given a static priority inversely based on its period. If a lower priority process is running, and a higher priority process becomes available to run, the lower priority process is interrupted.
the execution depends on the particular order in which the accesses take place.
- Readers-writers problem (5.7.2) is one of the classical problems of synchronization. Multiple reading processes and multiple writing processes need to share access to a single shared data resource.
- Resource allocation graph (7.2.2) is a graphical representation of processes i) requesting and ii) holding resources.
- Round-robin scheduling (6.3.4) is a preemptive schedule algorithms in which the Ready List is treated as a FIFO queue. Your answer needed to mention both the order in which processes are scheduled (FIFO) and preemption.
- Semaphore [p. 213]: An integer variable accessed only through the atomic operations wait() and signal().
- Swapping [p. 385]. Similar in concept to paging, except that the units are entire processes, rather than pages.
- Starvation [p. 217]: A process may wait indefinitely. Broader than just scheduling.
- SSTF = Shortest-seek-time-first [p. 474]; C-SCAN [p. 476].
- Thrashing [p. 4.25]. Behavior of a process that does not have "enough" page frames allocated to it, characterized by frequent page faults.
- Working set [p. ].
Wednesday:
Problem 2 Page Replacement Strategies
In a virtual memory system implemented by paging, when a page fault occurs,
we must bring in a new page. However, usually the operating system must choose
a page to be removed from memory to make room for the newly-referenced page.
- (7 points) Describe each of the following page replacement
strategies:
- First-in, first-out (FIFO) page replacement
- Optimal page replacement
- Least recently used (LRU) page replacement
- Least frequently used (LFU) page replacement
- FIFO: The page selected for replacement is the one which has been in memory the longest
- Optimal: Select the victim so that the run has the fewest page faults.
Not necessarily the page next used furthest in the future
- LRU: Victim is the page with longest time since last access
- LFU: Victim is the page used least frequently
- (6 points) Give at least one advantage (+) and one disadvantage (-) of each of the following page replacement strategies:
- First-in, first-out (FIFO) page replacement
- Optimal page replacement
- Least recently used (LRU) page replacement
- Least frequently used (LFU) page replacement
- FIFO: +: Simple, fair
-: Can be very bad
- Optimal: +: Best performance
-: Impossible to implement
- LRU: +: Good performance
-: Expensive to implement
- LFU: +: Intuitive?
-: Probably remove the page you just brought in
- (12 points) Now, work out a simple example.
Suppose our process is allocated three
(0 - 2) page frames in physical memory.
Suppose our process consists of nine (0 - 8) pages in its virtual
memory
The table shows the order in which pages are referenced in the execution of the program.
Complete the table by showing the number of each page residing in each
frame after each page reference shown under each of the page replacement
strategies
Mark each page fault with an asterisk (*)
For each strategy, how many page faults were generated, including the
three page faults already shown (denoted by *).
You should do your work here and hand in your exam.
| i) First-in, first-out (FIFO) page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
| | | | | |
| | | | | |
| | Frame 1: |
| 1* | 1 | | | |
| | | | | |
| | | | | |
| | Frame 2: |
| | 2* | | | |
| | | | | |
| | | | | |
| | Total number of
page faults: | |
| |
| ii) Optimal page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
| | | | | |
| | | | | |
| | Frame 1: |
| 1* | 1 | | | |
| | | | | |
| | | | | |
| | Frame 2: |
| | 2* | | | |
| | | | | |
| | | | | |
| | Total number of
page faults: | |
| |
| iii) Least recently used (LRU) page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
| | | | | |
| | | | | |
| | Frame 1: |
| 1* | 1 | | | |
| | | | | |
| | | | | |
| | Frame 2: |
| | 2* | | | |
| | | | | |
| | | | | |
| | Total number of
page faults: | |
| i) First-in, first-out (FIFO) page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
3* | | | | 0* | |
| | | 8* | | |
| | Frame 1: |
| 1* | 1 | | | |
| 4* | | | | 6* |
| | | | 0* | |
| | Frame 2: |
| | 2* | | | |
| | | 5* | | |
| 7* | | | | 6* |
| | Total number of
page faults: | 12 |
| |
| ii) Optimal page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
| | | | | |
| | | | | |
| | Frame 1: |
| 1* | 1 | | | |
3* | 4* | | 5* | | 6* |
| | | | | |
| | Frame 2: |
| | 2* | | | |
| | | | | |
| 7* | | 8* | | |
| | Total number of
page faults: | 9 (Can
select some different victims among pages
never to be used again) |
| |
| iii) Least recently used (LRU) page replacement |
| | Page references: |
0 | 1 | 2 | 0 | 1 |
2 | 3 | 4 | 2 | 5 |
0 | 6 | 0 | 7 | 7 |
8 | 0 | 6 |
| | Frame 0: |
0* | 0 | 0 | | | |
3* | | | 5* | | |
| 7* | | | | 6* |
| | Frame 1: |
| 1* | 1 | | | |
| 4* | | | 0* | |
| | | | | |
| | Frame 2: |
| | 2* | | | |
| | | | | 6* |
| | | 8* | | |
| | Total number of
page faults: | 11 |
Friday:
Problem 2 Process Scheduling Strategies
We are concerned with scheduling of processes to run on a single CPU.
- Describe each of the following CPU scheduling algorithms:
- First-Come, First-Served
- Shortest-Job-First
- Priority
- Round-Robin
- Multi-Level Queue
- Give at least one advantage (+) and one disadvantage (-) of each of the following CPU scheduling algorithms:
- First-Come, First-Served
- Shortest-Job-First
- Priority
- Round-Robin
- Multi-Level Queue
- Suppose you are designing the CPU scheduling algorithm for a patient monitoring device with a single processor. We do not yet know exactly what vital signs our instrument will monitor, but it will monitor 4-10 different vital signs. Each vital sign will have several sensors, an analysis component, and display in a dedicated window of a computer screen.
What CPU processing strategy will you use? Explain.
[If you have no biomedical sensitivities, the system will have 10-50 processes. Some (sensor readings) need very short CPU bursts very frequently. Some (display) need short CPU bursts, but far (1-5 sec.) apart. Some (analysis) need most of the processing power, but they can be interrupted and resumed.]
- See Section 6.3.
- See Section 6.3.
- The danger here is that any stochastic behavior may not support necessary service level guarantees. Our scheduling algorithm must be predictable.
My first choice is "None of the above." I'd design an interrupt-driven system.
My second choice is priority scheduling with preemption. The timer quantum should be larger than a burst needed by either sensor of display tasks. Also, a newly-arrived, high priority process should interrupt the running process. That is not the usual implementation, but it is essential to prevent the analysis task from causing sensor readings to be missed.
Another choice is a variant of SJF, with no pre-emption. Usually, we do not know in advance how long a process needs to run, but with careful design, in this case, we should be able to give reliable estimates. With SJF, the analysis tasks will need to relinquish the processor voluntarily.
Multi-level queue is also workable, provided newly-arrived high priority processes interrupt a running low priority process (analysis).
If you rely on a scheduler (no interrupts), it takes some care to arrange for the sensor reading tasks to be there when they are needed and not to be preempting when they are not. Really, you need interrupts.
Wednesday:
Problem 3 Process Synchronization - Critical-Section Problem with TestAndSet
Background:
Suppose we have an atomic operation TestAndSet(), which works as if it were implemented by pseudocode such as (Figure 6.4 from our text)
boolean TestAndSet(boolean *target) {
boolean rv = *target;
*target = TRUE;
return rv;
}
The function BoundedWaitingMutualExclusion (pseudocode adapted from Figure 6.8 from our text) claims to solve the critical-section problem:
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15: | |
void BoundedWaitingMutualExclusion(int i, int j, int n) {
boolean key;
while (TRUE) {
waiting[i] = TRUE;
key = TRUE;
while (waiting[i] && key) { key = TestAndSet(&lock); }
waiting[i] = FALSE;
{
// CRITICAL SECTION - ASSUME INTERRUPT
}
j = (i + 1) % n;
while ( (j != i) && !waiting[j] ) { j = (j + 1) % n; }
if (j == i) { lock = FALSE; }
else {waiting[j] = FALSE; }
{
// REMAINDER SECTION
}
}
} |
We have two processes which share memory. Each calls BoundedWaitingMutualExclusion():
| Process Alice | | Process Bob |
|---|
Memory region shared by both processes: #define N 2
boolean waiting[N]; // Assume initialized all FALSE
boolean lock = FALSE; |
|
1:
2:
3: | |
#define ME 0
int j = 0;
BoundedWaitingMutualExclusion(ME, j, N);
| | 1:
2:
3: | |
#define ME 1
int j = 1;
BoundedWaitingMutualExclusion(ME, j, N); |
Questions:
- A solution to the critical-section problem must satisfy what requirements? List them.
- At BoundedWaitingMutualExclusion() line 6, what is the purpose of the while(...) loop?
- At BoundedWaitingMutualExclusion() line 10, what is the purpose of the while(...) loop?
- Assuming Process Alice runs first, step carefully through the execution until each process has completed one pass through its critical section. Show values at each step for all local and all shared variables. Assume a context swap occurs in the middle of the CRITICAL SECTION and that any busy waiting eventually is interrupted for a context swap.
Worksheet for Problem 3
You should do your work here and hand in your exam.
| Process Alice | Shared | Process Bob |
|---|
| Code line | i | j | key |
waiting | lock |
Code line | i | j | key |
| A 2: | | 0 | |
[F, F] | F |
| | | |
| BWME(0, 0, 2) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 3: (T) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 4: | 0 | 0 | |
[T, F] | F |
| | | |
| | | | |
| |
| | | |
| BWME(0, 0, 2)BWME(0, 0, | 0 | 0 | 0 |
| |
BWME(0, 0, 2)BWME(0, 0, | 0 | 0 | 0 |
- (5 points) See page 228 or 230. We must show that
- Mutual exclusion is preserved;
- The progress requirement is satisfied; and
- The bounded waiting requirement is met.
"No busy waiting" is NOT a requirement. Busy waiting is a concern for performance, not for correct functioning.
- (3 points) Wait until no other process is in its critical section AND it is this process's turn among those waiting. Enforces Mutual Exclusion and Bounded Waiting.
- (3 points) Cycle through waiting processes. The loop cycles through non-waiting processes, stopping at a waiting process. The result is to set the index to the next waiting process. The purpose is to prevent the same process from re-entering its critical section repeatedly, starving an unlucky process is waiting, but never gets the CPU when the way is clear. Enforces Bounded Waiting.
- (14 points) Details of your answer depend on when you let context swaps occur. See the discussion on pages 233 - 234. In grading, I was more concerned with whether you followed what the code does than with whether you interrupted exactly when I intended. If you interrupted Process Alice during her CRITICAL SECTION and then ran Process Bob until he encountered a busy wait, you were more likely to discover what the loop at line 10 is doing.
See this simulation app that lets you step through this code.
One scenario is:
| Process Alice | Shared | Process Bob |
|---|
| Code line | i | j | key |
waiting | lock |
Code line | i | j | key |
| A 2: | | 0 | |
[F, F] | F |
| | | |
| BWME(0, 0, 2) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 3: (T) | 0 | 0 | |
[F, F] | F |
| | | |
| BWME 4: | 0 | 0 | |
[T, F] | F |
| | | |
| BWME 5: | 0 | 0 | T |
[T, F] | F |
| | | |
| BWME 6: (T & T) => T | 0 | 0 | F |
[T, F] | T |
Note: Line 6 is executed twice | | | |
| BWME 6: (T & F) = > F | 0 | 0 | F |
[T, F] | T |
| | | |
| BWME 7: | 0 | 0 | F |
[F, F] | T |
| | | |
| BWME 8: CRITICAL | 0 | 0 | F |
[F, F] | T |
| | | |
| context swap |
| | | | |
[F, F] | T |
B 2: | | 0 | |
| | | | |
[F, F] | T |
BWME(1, 0, 2) | 1 | 0 | |
| | | | |
[F, F] | T |
BWME 3: (T) | 1 | 0 | |
| | | | |
[F, T] | T |
BWME 4: | 1 | 0 | |
| | | | |
[F, T] | T |
BWME 5: | 1 | 0 | T |
| | | | |
[F, T] | T |
BWME 6: (T & T) => T | 1 | 0 | T |
| | | | |
[F, T] | T |
BWME 6: (T & T) => T | BUSY WAIT until |
| context swap |
| BWME 8: CRITICAL | 0 | 0 | F |
[F, T] | T |
| | | |
| BWME 9: | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 10: (T & F) => F | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 11: (F) | 0 | 1 | F |
[F, T] | T |
| | | |
| BWME 12: | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 13: REMAINDER | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 3: (T) | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 4: | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 5: | 0 | 1 | T |
[T, F] | T |
| | | |
| BWME 6: (T & T) => T | 0 | 1 | T |
[T, F] | T |
| | | |
| BWME 6: (T & T) => T | Forced to take turns
BUSY WAIT until |
[T, F] | T |
| | | |
| context swap |
| | | | |
[T, F] | T |
BWME 6: (F & T) => F | 1 | 0 | T |
| | | | |
[T, F] | T |
BWME 7: | 1 | 0 | T |
| | | | |
[T, F] | T |
BWME 8: CRITICAL | 1 | 0 | T |
| context swap |
| BWME 6: (T & T) => T | Forced to take turns
BUSY WAIT until |
[T, F] | T |
| | | |
| context swap |
| Your solution could end here after 1 complete CRITICAL SECTION in each process | |
[T, F] | T |
BWME 9: | 1 | 1 | T |
| | | | |
[T, F] | T |
BWME 10: (F & T) => F | 1 | 1 | T |
| | | | |
[T, F] | F |
BWME 11: (T) | 1 | 1 | T |
| | | | |
[T, F] | F |
BWME 13: REMAINDER | 1 | 1 | T |
| context swap |
| BWME 6: (T & T) => T | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 6: (T & F) => F | 0 | 1 | F |
[T, F] | T |
| | | |
| BWME 7: | 0 | 1 | F |
[F, F] | T |
| | | |
| BWME 8: CRITICAL | 0 | 1 | F |
[F, F] | T |
| | | |
| etc. |
Friday:
Problem 3 Process Synchronization - Allocate and Release
Consider the code example for allocating and releasing processes:
01 #define MAX_PROCESSES 255
02 int number_of_processes = 0;
03
04 /* The implementation of fork() calls this function */
05 int allocate_process() {
06 int new_pid;
07
08 if (number_of_processes == MAX_PROCESSES)
09 return -1;
10 else {
11 /* Allocate necessary process resources */
12 ++number_of_processes;
13
14 return new_pid;
15 }
16 }
17
18 /* The implementation of exit() calls this function */
19 void release_process() {
20 /* Release process resources */
21 --number_of_processes;
22 }
- Identify the race condition(s).
- Assume you have a mutex lock named mutex with the operations acquire() and release(). Indicate where the locking needs to be placed to prevent the race condition(s).
- Could we replace the integer variable
int number_of_processes = 0;
with the atomic integer (operations ++ and -- are atomic operations)
atomic_t number_of_processes = 0;
to prevent the race condition(s)? Explain.
See Problem 5.20, p. 246-7. We are assuming several processes could be simultaneously allocating and releasing processes.
- Test at Line 08 with Lines 12 and 21.
-
01 #define MAX_PROCESSES 255
02 int number_of_processes = 0;
mutex_lock mutex;
03
04 /* The implementation of fork() calls this function */
05 int allocate_process() {
06 int new_pid;
07
acquire(mutex);
08 if (number_of_processes == MAX_PROCESSES)
release(mutex);
09 return -1;
10 else {
11 /* Allocate necessary process resources */
12 ++number_of_processes;
release(mutex);
13
14 return new_pid;
15 }
16 }
17
18 /* The implementation of exit() calls this function */
19 void release_process() {
20 /* Release process resources */
acquire(mutex);
21 --number_of_processes;
release(mutex);
22 }
Placing release(mutex) after line 15 does NOT work; you have returned before releasing.
- No. That would address the races at Lines 12 and 21, but not the test at Line 08.
I expected most students would see the ++ and --, but miss the ==. Only a couple missed the == participation. Well done.
Wednesday:
Problem 4 Disk Scheduling Algorithms
- Suppose that a rotating magnetic disk drive has 5,000 cylinders, numbered 0 to 4,999. The drive currently is serving a request at cylinder 2,150, and the previous request was at cylinder 1,805. The queue of pending requests, in FIFO order, is:
2,069, 1,212, 2,296, 2,800, 544, 1,618, 356, 1,523, 4,965, 3,681.
Starting from the current head position, what is the total distance (in cylinders) that the disk arm moves to satisfy all the pending requests for each of the following disk scheduling algorithms?
- FCFS
- SSTF
- SCAN
- LOOK
- What is unrealistic about part a)?
- Problem 10.11, p. 498
- FCFS: Serve cylinders 2150, 2069, 1212, 2296, 2800, 544, 1618, 356, 1523, 4965, 3681.
Moves of 81, 857, 1084, 504, 2256, 1074, 1262, 1167, 3442, 1284.
Total moves = 13,011
- SSTF: Serve cylinders 2150, 2069, 2296, 2800, 3681, 4965, 1618, 1523, 1212, 544, 356.
Moves of 81, 227, 504, 881, 1284, 3347, 95, 311, 668, 188.
Total moves = 7586
- SCAN: Serve cylinders 2150, 2296, 2800, 3681, 4965, 4999, 2069, 1618, 1523, 1212, 544, 356.
Moves of 146, 504, 881, 1284, 34, 2930, 451, 95, 311, 668, 188.
Total moves = 7492
- LOOK: Serve cylinders 2150, 2296, 2800, 3681, 4965, 2069, 1618, 1523, 1212, 544, 356.
Moves of 146, 504, 881, 1284, 2896, 451, 95, 311, 668, 188.
Total moves = 7424
- Surely, additional requests will arrive while our disk is serving the currently enqueued 10 requests.
A platter is served by one read/write head. The answer to this question is the same no matter how many platters comprise the disk. A cylinder is the name given to the set of tracks from each platter having the same radius. Typically, the read/write heads for each platter move together, simultaneously accessing a cylinder of data.
Yes, the problem would be a more realistic measure of total data latency if it had included rotational latency, but delays from rotational latency are added to the seek latencies addressed by this problem. That is, adding rotational latencies would make the problem significantly harder and not offer significantly more insight.
Friday:
Problem 4 Disk Scheduling Algorithms
Suppose we are programming the on-board controller for a modern rotating hard disk. We are to design the algorithm used to schedule disk requests we receive from the operating system. The high-level organization resembles:
- Receive service requests from the operating system.
- Undo the lies we tell the OS by translating requests from the coordinates the OS believes into the actual, physical coordinates of the drive.
- Insert each new request (Cylinder, Platter, Sector) into an appropriate ListOfPendingRequests.
- Whenever the disk is not busy serving a request, select the next request for service from the ListOfPendingRequests.
- The disk hardware services that request.
We assume that the disk is fast enough that the average number of requests in the ListOfPendingRequests is bounded (say by 50, although that number makes no difference to your answer).
We assume that the disk is slow enough that the average number of requests in the ListOfPendingRequests is more than one, so Step 4 usually has a selection to make.
This question concerns only Step 4, "Select the next request for service."
- List and describe five strategies/algorithms that might be considered at Step 4 for selecting the next request for service.
- Which of the five would you choose?
- Explain why.
- Would your choice be different if we were working on a flash or solid state drive? Explain.
- (10 points) See Section 10.4, p. 472 ff. You should list and describe First-Come, First-Served (FCFS), Shortest Seek Time First (SSTF), SCAN, C-SCAN, and LOOK.
- (3 points) Probably some variant of LOOK or C-LOOK.
- (8 points) I expect an understanding that there are trade-off. Criteria include simplicity, "fairness," average wait time, variability of wait time, no starvation, throughput, and preserving the semantics of writing and reading.
- (4 points) Probably use FCFS, except attempting to group accesses to the same large block. Probably give priority to reads over writes, being careful to preserve the semantics.
Wednesday:
Problem 5 Directories and Files
For this problem, assume that information about a file is stored in a File Control Block, and information about a directory is stored in a Directory Control Block. For this problem, we only consider the File Control Block and the Directory Control Block as stored on the disk; File Control Blocks and Directory Control Blocks also are stored in memory as operating systems data structures, but they do not concern us here.
- List five attributes of both files and directories.
- List one attribute of files that does not apply to directories.
- List one attribute of directories that does not apply to files.
- List five services of both files and directories.
This is a generic question about the concepts. It is not about whether a specific OS keeps track of certain attributes or provides certain services.
"We only consider the File Control Block and the Directory Control Block as stored on the disk." Hence, no attributes in your answer should consider memory.
Hmm ... I intended "attributes" in the object-oriented sense. That is how most interpreted it, but I cannot object, I guess, if you made an English interpretation.
- See Section 11.1.1, p. 504-506
- Type (except "directory" might be considered a type)
Not "executable." In a UNIX system, you must have execute permission on a directory to see its contents.
- isDirectory, parent, children
- See Section 11.1.2, p. 506
"Extension" is an ambiguous file attribute; it has (at least two meanings): fileName.ext and an association of the application to open it. Historically, Windows use 3 character "extensions", separated from the file name by a dot "." character, to indicate the application with which that file is associated. While that meaning is still in common use, that is not quite how Windows works now. A Windows (and other OSs) file name can include several dots, and users may over-ride the default application associations. For example, you can have Excel open HTML files when you double-click them. I do that with some HTML files containing tables I'd like to sort in Excel.
If you answered b) with "Extensions, e.g., .jpeg", you lost a couple points because you can have a directory MyVacationPhotos.jpeg. If you suggested "extension" in the sense of application association, I accepted that. However, I could argue that if you double-click on a folder (directory) and your file explorer GUI responds. folders/directories are associated with your file explorer, an application association (extension).
My intent was that there should be one "easy" question on the exam. If you did not get to this question, perhaps you should heed the advice to read the entire exam before you begin.
Friday:
Problem 5 Directories and Files
The open-file table is used by the operating system to maintain information about files that currently are open. Should the operating system maintain a separate table for each user or maintain just one table that contains references to files that currently are being accessed by all users? If the same file is being accessed by two different users or programs, should there be separate entries in the open-file table? Explain.
See Problem 11.10, p. 540.
This is a difficult question to cover all your bases. There are no short, simple, correct answers.
What does it mean for a file to be open? For simplicity, let's assume the file is open for sequential access, although the access may be either Read or Write:
- Some information about the file must be in memory, not just on disk, so we need a memory version of a File Control Block.
- We need a cursor telling where we are in the file.
- We need a buffer from which we are reading or to which we are writing.
- We need to close the file when we are done.
Suppose we use a separate table of open files for each process. We cannot know in advance how many files a process may need, so our open file "table" must be a dynamic list, probably of in-memory File Control Blocks, with head and tail being fields in the Process Control block. When a process is terminated, we can write all its pending disk write requests and close all its open files. When a file is closed, its in-memory File Control Block can be released, after any necessary updates are made to the on-disk File Control Block.
That is workable, and it probably works well, unless two or more processes have the same file open (assume both for read, to avoid worrying about race conditions)? Ah, but how do we know if another process already has the file open for writing? We'd have to look through the open file table for all processes. That could be very expensive.
OK. To make it easier to tell if two processes are trying to open the same file, whether for read or write, we consider maintaining one system-wide open file table for all processes, probably a linked list of in-memory File Control Blocks. Each Process Control Block needs a list of files it has open, a cursor, and a data buffer, and each File Control Block needs a list of processes accessing it, or at least a count of processes using it.
Of course, if we use one system-wide open file table for all processes, we must provide protection from a process accessing files it did not open.
Now, when a process opens file foo.bar, we first examine the system-wide open file table to see whether foo.bar is already open. If it is not, we create an in-memory File Control Block for foo.bar and add it to the system-wide open file table. If foo.bar is already open by another process, we ask whether the indented modes are compatible (two READs are OK; a Read and a Write or two Writes probably are not). If the intended mode is permitted, we increment the count of processes using it.
Suppose a process using file foo.bar closes it. Do we remove the File Control Block for foo.bar from the system-wide open file table? Only if it is the last process using that file.
Does it make sense to allow two (or more) processes to have Write access to the same file? For sequential access, the semantics do not make sense, but multiple simultaneous writes using direct or indexed access can be made to work.
Another interesting use case considers a large database file being queried simultaneously by many client processes.
Another interesting use case is Google docs. In some sense, Google supports many simultaneous writes. We may talk about how that can work later in the semester.
There are more complications, but that should give an idea.
Whichever variant you recommended, per-process open file table of system-wide open file table, you must acknowledge some of the consequences following from your recommendation.
| |