| |
Your second midterm examination will appear here. It covers through Section 9.6.
Section 7.5 is explicitly omitted.
It will be a period-long, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Questions will be similar to homework questions from the book. You will
be given a choice of questions.
I try to ask questions I think you might hear in a job interview. "I
see you took a class on Operating Systems. What can you tell me about ...?"
See also Dr. Barnard's notes.
He was using a different edition of our text, so chapter and section numbers
do not match, but his chapter summaries are excellent.
Results on exam 1 suggest you may wish to maintain a vocabulary list.
Directions:
Read and follow the directions.
- Write on four of the five questions. If you write more
than four questions, only the first four will be graded. You do not get
extra credit for doing extra problems.
- Read the entire exam. If there is anything you do not understand about
a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly
what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of
paper. [Or -5]
- Be sure I can read what you write.
- Write only on one side of a sheet.
- Be sure your name is on each sheet of paper you hand
in. [Or -5]
- If I ask questions with parts
- . . .
- . . .
your answer should show parts
- . . .
- . . .
Score Distribution:
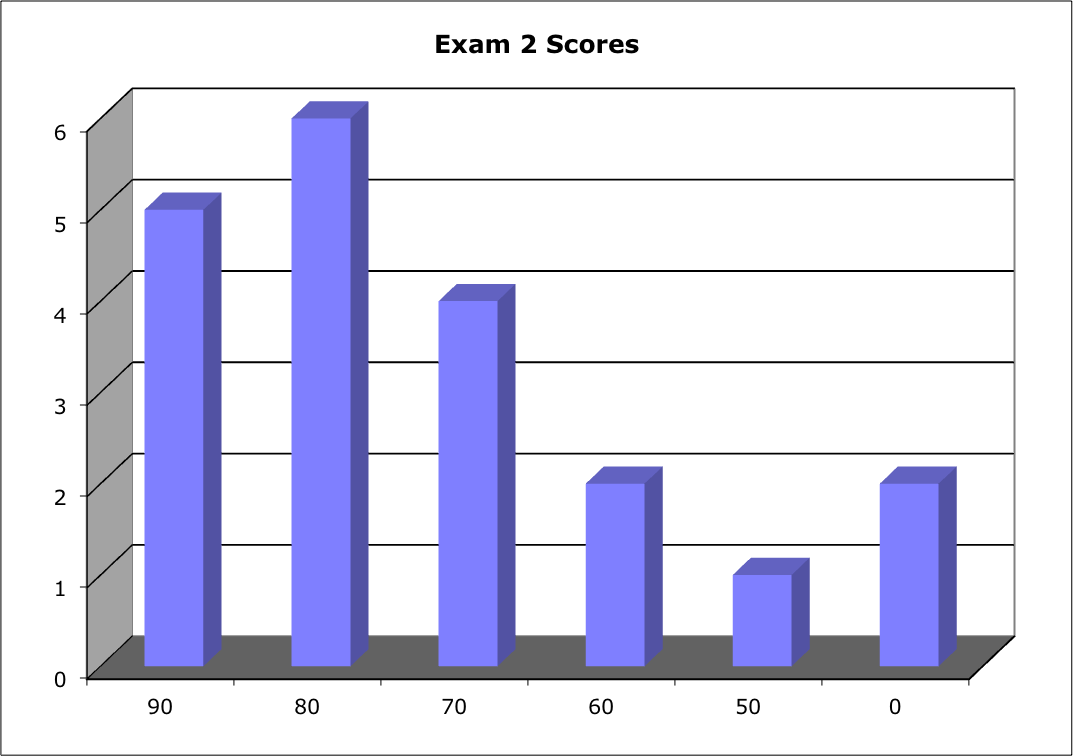
Median: 80; Mean: 74.8; Standard Deviation: 25.4
Students scoring higher than on Exam 1: 17; lower: 7
These shaded block are intended to suggest solutions; they are not intended to be complete solutions.
Problem 1 Definitions
Give careful definitions for each term (in the context of computer operating systems) (5 points for each part):
- Process vs. thread
- Processor affinity vs. load balancing
- Deadlock vs. starvation
- Monitor vs. semaphore (for mutual exclusion)
- Thrashing vs. page fault (in the context of memory management)
Hint: A definition is 1 - 2 sentences.
- Process vs. thread. See p. 101-102, 153. A process is a program in execution. A process may include several threads. A thread is a basic unit of CPU use. It includes a thread ID, a program counter, a register set, and a memory stack.
- Processor affinity vs. load balancing. Both concern multi-processor scheduling. See pp. 202 - 204. Processor affinity suggests a process should remain on the same processor to exploit caching. Load balancing suggests a process should be moved from an overloaded processor to a lightly loaded processor.
- Deadlock vs. starvation. Both concern indefinite wait. See p. 204. "A set of processes is in a deadlocked state when every process in the set is waiting for an event that can be caused only by another process in the set." Starvation is also an indefinite wait not satisfying the definition of deadlock, often due to an accidental sequence of events. Starvation can occur in circumstances besides in the ready list.
- Monitor vs. semaphore (for mutual exclusion). See Section 6.7 vs. 6.5. Both are means to enforce mutual exclusion. "The monitor construct ensures that only one process at a time can be active within the monitor." In Java, the keyword synchronized enforces a monitor-like discipline. Counting or binary semaphores provide mutual exclusion through indivisible operations wait() and signal().
- Thrashing vs. page fault: See p. 363, 386. A page fault occurs when the page for a memory reference is not found in the page table. Thrashing occurs when a process does not have "enough" page frames. Page faults occur frequently, often throwing a page out, only to bring it back quickly.
Warning: On the final exam, any definition that starts "Z is when ...," or "Z is where ..." earns -5 points, unless Z is a time or a place, respectively.
Problem 2 "Cooperative" Process Scheduling
One reason for using a quantum to interrupt a running process after a "reasonable"
period of time is to allow the operating system to regain the processor and
dispatch the next process. Suppose a system does not have an interrupting
clock, and that the only way a process can lose the processor is to
relinquish it voluntarily. Suppose that no dispatching (scheduling) mechanism is provided
in the operating system.
- (15 points) Describe how a group of user processes could cooperate among themselves
to effect a user-controlled dispatching mechanism.
- (10 points) What potential dangers would be inherent in this scheme?
- (10 points) What are the advantages to the users over a system-controlled dispatching
scheme?
This is exactly how many real-time systems are programmed. It works well for embedded systems with only one or a small number of processes.
In standard, quantum-driven time-sharing systems, few processes use
their allotted quantum. Most processes leave the Running state when they
block themselves by requesting some resource. Hence, the design proposed
here does not make a BIG difference in typical operation.
a) How can processes cooperate?
Describe how this CAN work.
Do NOT make each process keep track of time or operation counts, or we may as well be timer interrupt driven.
In practice, real-time processes do what they must do, then block themselves to let the next process run. Sometimes, there is a scheduler; often, a running process explicitly invokes the next one.
Frequent error: if one process is running, there is nothing any other process can do.
b) Dangers?
A process does NOT give up the CPU
c) Advantages?
- Efficient - low overhead
- Precise control - not interrupted in the middle of critical processing
- Precise control - very flexible selection of next process
- Mutual exclusion is easy: You do your critical section before you call blockMe()
- Simpler operating system
If the currently running process directly invokes the next, there is no need for a scheduler. The scheduling mission is built into the design.
Grading Criteria
C -- Give at least one advantage and one danger
B -- Describe a method for cooperation
Problem 3 Virtual Memory: Effective Memory Access Time
Assumptions:
- We are using a virtual memory memory system with paging
- At any point in the execution of our process, some pages are in memory
(and on the paging disk), and some pages are only on the paging disk
- Part of the page table is kept in a Translation Lookaside Buffer (TLB),
and part is kept in memory. [Don't panic; you do not need to know what a
TLB is to answer this question.]
- It takes 10 nanoseconds to access the TLB
- It takes 100 nanoseconds to access memory
- It takes 100,000 nanoseconds to access the disk
- For each memory reference in our program, we first look in the TLB (10
ns)
- 90% of the time, we find in the TLB the frame number in memory where the
desired reference can be found, and we access memory to find it (+ 100 ns)
- 10% of the time, we do not find the desired page in the TLB
- In that case, we must access memory to find the page table (+ 100 ns)
- 80% of that 10% (8% of the total), we find the frame number in memory
where the desired reference can be found, and we access memory to find it
(+ 100 ns)
- In the remaining 2% of the time, we have not found the frame number either
in the TLB or in the in-memory page table because the referenced page is
not in memory. We must go to the disk and retrieve it (+ 100,000 ns)
- In 15% of the cases described in assumption 12, before we can bring the
new page in, we must first copy the "victim" page currently holding that
frame back to the disk (+ 100,000 ns)
- Once the new page is copied from the disk into its page frame in memory,
we must access the referenced memory location (+ 100 ns)
Questions:
- (2 points) What is the event called described in assumption 9?
- (2 points) What is the event called described in assumption 12?
- (3 points) In assumption 13, why must we sometimes write the victim page
back to the disk?
- (3 points) In assumption 13, why don't we always have to write the victim
page back to the disk?
- (10 points) On average, how many nanoseconds are required to make 1,000
memory references in this system?
- (5 points) If you wish to make the average memory access time faster, which
of these steps will you attack? Why? What operating system changes might improve
that part?
- TLB miss
- Page fault
- Its contents may have changed since it was read (or last written)
- Its contents may not have changed since it was read (or last written)
| Assumption | Time each (ns) | Times of 1000 | Time total (ns) |
| 7 |
10 |
1000 |
10,000 |
| 8 | 100 | 900 | 90,000 |
| 10 | 100 | 100 | 10,000 |
| 11 | 100 | 80 | 8,000 |
| 12 | 100,000 | 20 | 2,000,000 |
| 13 | 100,000 | 3 | 300,000 |
| 14 | 100 | 20 |
2,000 |
| Total | | |
2,420,000 |
I included this question because scientists and engineers should always be thinking quantitatively, asking "How much?" Without numbers, we are artists. "Faster," is an answer from Marketing; "1.8 times as fast," is an answer from Science & Engineering.
- Clearly, the cost of disk access dominates the total. You have three alternatives:
- Make disk access faster (reduce the 100,000)
- Fewer page faults (reduce the 20):
Larger memory
Larger working set for this process
Better page replacement strategy
- Fewer write-backs (reduce the 3)
Implement "sneaky write" on dirty bit
More frequent write-back to clear dirty bit
You might also reduce the TLB miss rate:
Larger TLB
Better TLB replacement strategy
Of course, more or faster memory would help, but that's not an OS improvement.
Reduce various forms of misses so you do not have to go ot the disk so often? Yes, that would help, but we are only going to the disk 2% of the time. That's pretty good and probably hard to improve much.
Problem 4 Page Replacement Strategies
In a virtual memory system implemented by paging, when a page fault occurs, we must bring in a new page. However, usually the operating system must choose a victim page to be removed from memory to make room for the newly-referenced page.
- (5 points) Describe each of the following page replacement strategies:
- First-in, first-out (FIFO) page replacement
- Optimal page replacement
- Least recently used (LRU) page replacement
- Least frequently used (LFU) page replacement
- FIFO: The page selected for replacement is the one which has been in memory the longest
- Optimal: Select the victim so that the run has the fewest page faults. Not necessarily the page next used furthest in the future
- LRU: Victim is the page with longest time since last access
- LFU: Victim is the page used the least number of times
Beware of circular definitions, such as "Least recently used is least
recently used."
- (5 points) Give at least one advantage (+) and
one disadvantage (-) of each of the following page replacement strategies:
- First-in, first-out (FIFO) page replacement
- Optimal page replacement
- Least recently used (LRU) page replacement
- Least frequently used (LFU) page replacement
- FIFO: +: Simple, fair
-: Can be very bad
- Optimal: +: Best performance
-: Impossible to implement
- LRU: +: Good performance
-: Expensive to implement
- LFU: +: Intuitive?
-: Probably remove the page you just brought in
Several students said, "No page is victimized." False. Each of these strategies selects a "victim" to be removed from memory so a newly-requested page can be brought in.
- (10 points) Now, work out a simple example.
Suppose our process is allocated four (0 - 3) page frames in
physical memory.
Suppose our process consists of eleven (1 - 11) pages in its virtual
memory.
The table shows the order in which pages are referenced in the execution
of the program.
Complete the table by showing the number of each page residing in
each frame after each page reference shown under each of the page
replacement strategies.
Mark each page fault with an asterisk (*).
How many page faults were generated,
including the three page faults already shown (denoted by *)
Hint: You are welcome to rip this page off the exam packet, put your name on it, complete the table on this copy, and hand it in with your exam solutions.
| Least recently used (LRU) page replacement |
| |
Page references: |
1 |
2 |
3 |
4 |
5 |
3 |
4 |
1 |
6 |
7 |
8 |
7 |
8 |
9 |
7 |
8 |
9 |
5 |
4 |
5 |
4 |
2 |
| |
Frame 0: |
1* |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Frame 1: |
|
2* |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Frame 2: |
|
|
3* |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Frame 3: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| |
Total number of
page faults: |
|
Here is what I get. "*" denotes a page fault; "+" denotes a page hit/access. If you do not pay attention to accesses of pages already in memory, you get FIFO, not LRU:
| Least recently used (LRU) page replacement |
| |
Page references: |
1 |
2 |
3 |
4 |
5 |
3 |
4 |
1 |
6 |
7 |
8 |
7 |
8 |
9 |
7 |
8 |
9 |
5 |
4 |
5 |
4 |
2 |
| |
Frame 0: |
1* |
1 |
1 |
1 |
5* |
5 |
5 |
5 |
6* |
6 |
6 |
6 |
6 |
6 |
6 |
6 |
6 |
5* |
5 |
5+ |
5 |
5 |
| |
Frame 1: |
|
2* |
2 |
2 |
2 |
2 |
2 |
1* |
1 |
1 |
1 |
1 |
1 |
9* |
9 |
9 |
9+ |
9 |
9 |
9 |
9 |
9 |
| |
Frame 2: |
|
|
3* |
3 |
3 |
3+ |
3 |
3 |
3 |
7* |
7 |
7+ |
7 |
7 |
7+ |
7 |
7 |
7 |
4* |
4 |
4+ |
4 |
| |
Frame 3: |
|
|
|
4* |
4 |
4 |
4+ |
4 |
4 |
4 |
8* |
8 |
8+ |
8 |
8 |
8+ |
8 |
8 |
8 |
8 |
8 |
2* |
| |
Total number of
page faults: |
13 |
- (5 points) Now I tell you that pages 1 - 4 are code pages (never written),
pages 5 - 7 are read-only data pages, and pages 8 and 9 are very frequently
written
data pages.
- Is "number of page faults" still the best metric for evaluation of page replacement strategies? Explain.
- Suggest a modification of LRU that improves its performance for this example.
The metric we really care about is time. In this scenario, selecting page 8
or 9 as a victim is roughly twice as expensive as selecting one of pages 1
- 7 because the victim page must first be written back to the disk before
it can be replaced.
One modification to LRU is to consider the time since page last accessed for pages 8 and 9
to be half their true value. That biases the selection away from those pages. To be selected
as a victim, page 8 or 9 must not be accessed for twice as long as the next candidate.
You could also argue that no modification is necessary. Since I said pages
8 and 9 are accessed "very frequently," they will never be selected as not
used recently.
Problem 5 Tricky C program
The code below assumes it is being run in XINU. It models the classic Dining Philosophers problem with MAXFORKS forks (represented by semaphores) and MAXFORKS philosophers (represented by processes). Each philosopher process has an assigned ID (0 <= i < MAXFORKS). This solution assigns to each philosopher process a different priority, equal to the ID value.
void philosopher(int id, semaphore forks[]) {
int myLeft, myRight;
myLeft = id;
myRight = (id + 1) % MAXFORKS;
while (1) {
printf("Philosopher %d thinks\n", id);
sleep(200);
wait(forks[myLeft]);
wait(forks[myRight]);
printf("Philosopher %d eats\n", id);
sleep(200);
signal(forks[myRight]);
signal(forks[myLeft]);
}
}
int main(int argc, char **argv) {
semaphore forks[MAXFORKS];
for (i = 0; i < MAXFORKS; i++) {
forks[i] = newsem(1);
ready(create((void *)philosopher, INITSTK, i, "PHIL",
2, i, forks), RESCHED_NO);
}
resched();
...
}
- Does this instance of the Dining Philosophers potentially deadlock? Explain.
- If not, make a rigorous argument for why not.
- If so, change the philosopher process to prevent deadlock. Explain.
Hint: You are welcome to rip this page off the exam packet, put your name on it, make your changes on this copy, and hand it in with your exam solutions.
Dr. Brylow writes:
The exam version has most of the output statements removed to make the code shorter,
but if you put a printf() after each wait() and signal(), you get something like:
Philosopher 4 has acquired left fork
Philosopher 3 has acquired left fork
Philosopher 2 has acquired left fork
Philosopher 1 has acquired left fork
Philosopher 0 has acquired left fork
and then deadlock.
Interestingly, as I was capturing the output for you above, I realized
that this question may be even subtler than I thought. I cleaned the output
statements out to make the code shorter for the exam, but that also
eliminates the deadlock. Without a potentially blocking I/O call between the
two wait() calls, nothing can stop the highest priority process from
acquiring both his forks if the scheduler is simple priority-based. Even if
he is preempted, priority scheduling indicates that the highest numbered
philosopher will be ready to run again before any lower priority
philosophers.
If the scheduler uses aging, or if there is any blockable call between
the two wait() calls, then deadlock becomes possible again.
But that's really just a quirky, non-circular property of this particular
deterministic implementation of the Dining Philosophers. If you add random
wait times into the mix, it is still possible for the highest priority
philosopher to get his first fork, but not the other, and then we have
potential circular wait again.
Ahhh, concurrence.
Corliss: I gave full credit to some solutions that said, "Yes," and full credit to some solutions that said, "No." I looked for a careful analysis.
| |