| |
It will be a two hour, closed book exam.
It covers Chapters 1 - 12, 16, and 17. Explicitly excluded are Sections 5.7, 6.9, 7.5, 9.7-9.8, 17.4-6. We have covered some material from
Chapters 14, 15, and 19 that might illustrate points you want to make, but
I will not explicitly ask questions from those chapters. It is a comprehensive
exam, with about half the questions coming from material since the second midterm exam.
No electronic devices of any kind are permitted.
Expectations:
- See course goals and objectives
- See objectives at the beginning of each chapter
- See Summary at the end of each chapter
-
See previous exams:
See also Dr. Barnard's notes.
He was using a different edition of our text, so chapter and section numbers
do not match, but his chapter summaries are excellent.
In the Table of Contents or the Index to the text, can you define/explain
each term?
On the final exam, any definition of the form "ZZZ is when ..."
loses half the available points, unless ZZZ refers to a time.
Directions:
Read and follow the directions.
- Write on five of the six questions. Each question is
worth 20 points. If you write more than five questions, only the first
five will be graded. You do not get extra credit for doing extra problems.
- Read the entire exam. If there is anything you do not understand about
a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly
what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of paper. [Or -5]
- You may write on and submit any of the pages of the exam itself.
- Be sure I can read what you write.
- Write only on one side of a sheet.
- Be sure your name is on each sheet of paper you hand in. [Or -5]
To grade, we separate the papers by problem, and we need to re-assemble YOUR exam.
Score Distribution:
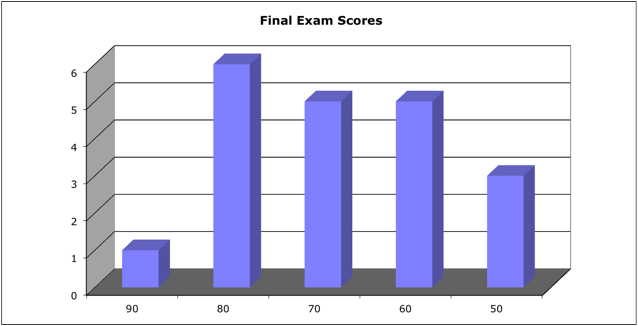
Median: 66; Mean: 68.2; Standard Deviation: 25.8
These shaded block are intended to suggest solutions; they are not intended to be complete solutions.
Problem 1 Tricky C
Here is a C function that might appear in the context of XINU memory management:
struct memblock
{
struct memblock *next; // pointer to next memory block
ulong length; // size of memory block (incl. struct)
};
// Allocates space using getmem(), and automatically hides accounting
// info in the two words below the returned memory region. This
// allows a corresponding call to free() not to require a request
// size parameter.
void *malloc(ulong nbytes)
{
struct memblock *block;
// Round request size to multiple of struct memblock.
nbytes = (nbytes + 7) % sizeof(struct memblock);
block = getmem(nbytes);
if (block = SYSERR ) return SYSERR;
// Back pointer up one slot.
block = block - sizeof(struct memblock);
// Store accounting info.
block.next = block;
block.length = nbytes;
// Return pointer to useful part of memory block.
return (block + sizeof(struct memblock));
}
What is wrong with this code?
Hint: The errors are many and varied. Identify as many as you can.
Some errors include:
- Initialize block
- Hard coded size
- Typecast for getmem()
- Assignment (=) vs. comparison (==)
- Do not back up - out of range?
- Pointer arithmetic is wrong
- Pad request size to getmem()
- Arrow operators
- . . .
Watch Code Monkey, song by Jonathan Coulton
Problem 2 Vocabulary - Acronyms
In the context of computer operating systems, for each acronym,
- give the phrase for which the acronym stands and
- give a one sentence definition or description
- SMP, p. 14: Symmetric Multi-Processor
- IPC, p. 116 ff.: Interprocess Communication
- RAID: Section 12.7: Redundant Arrays of Independent (or Inexpensive) Disks
- PCB, p. 103: Process Control Block
- RPC, p. 131: Remote Procedure Call
- POSIX: Portable Operating System Interface for Unix
- SJF, p. 189: Shortest Job First CPU scheduling algorithm
- TSR: Terminate and Stay Resident
- TLB, p. 333: Translation Look-aside Buffer
- LRU, p. 376: Least Recently Used
Problem 3 Disk scheduling
- List five strategies for scheduling read/write requests to a hard drive.
For each strategy,
- give its name (not just its abbreviation),
- describe how it works in a sentence or two,
- sketch a diagram illustrating how it works,
- list its advantages, and
- list its disadvantages.
- Assume a non-lying disk controller and disk assembly with
- Rotational speed of 4,000 rpm
- 8 platters
- 75 sectors per track (5,000 sectors read per second)
- 16,000 tracks per disk surface, numbered from the outside inward.
- Seek speed of 10,000 tracks per second
- 512 bytes per sector
- Time is measured in integer units of 1.0E-4 seconds (= time to seek one track)
- At time = 0, the disk is at track 8,000, at the beginning of sector 40
- At time = 0, the disk starts serving a request for track 8,000, sector 40
Suppose the disk controller receives the following sequence of disk read requests:
Time arrived
(1E-4 sec) | | Track | | Sector |
| 1 | | 8004 | | 55 |
| 10 | | 8201 | | 60 |
| 27 | | 8100 | | 40 |
| 130 | | 8016 | | 40 |
| 293 | | 8017 | | 44 |
Assuming a SSTF strategy, complete the following table showing the order in which each request is started and the time at which each request is started:
| Time | | Activity | | Track | | At
sector | | Want
sector | | Pending requests |
| 0 | | read | | 8000 | | 40 | | 40 | | |
| 2 | | seek | | 8004 | | 41 | | 55 | | [T: 8004, S: 55] |
| 6 | | rotate | | 8004 | | 43 | | 55 | | |
| 30 | | read | | 8004 | | 55 | | 55 | | |
| ... | | | | | | | | | | |
- See Section 12.4, p. 510 ff.
- 12.4.1 FCFS: First Come First Serve
- 12.4.2 SSTF: Shortest Seek Time First
- 12.4.3 SCAN (not an acronym)
- 12.4.4 C-SCAN: Circular SCAN
- 12.4.5 LOOK
- 12.4.5 C-LOOK
| Time | | Activity | | Track | | At
sector | | Want
sector | | Pending requests |
| 0 | | read | | 8000 | | 40 | | 40 | | |
| 2 | | seek | | 8004 | | 41 | | 55 | | [T: 8004, S: 55] |
| 6 | | rotate | | 8004 | | 43 | | 55 | | |
| 30 | | read | | 8004 | | 55 | | 55 | | [T: 8201, S: 60]; [T: 8100, S: 40] |
| 32 | | seek | | 8100 | | 56 | | 40 | | |
| 128 | | rotate | | 8100 | | 29 | | 40 | | |
| 150 | | read | | 8100 | | 40 | | 40 | | [T: 8201, S: 60]; [T: 8016, S: 40] |
| 152 | | seek | | 8016 | | 41 | | 40 | | |
| 236 | | rotate | | 8016 | | 8 | | 40 | | |
| 300 | | read | | 8016 | | 40 | | 40 | | [T: 8201, S: 60]; [T: 8017, S: 44] |
| 302 | | seek | | 8017 | | 41 | | 44 | | |
| 303 | | rotate | | 8017 | | 41.5 | | 44 | | |
| 308 | | read | | 8017 | | 44 | | 44 | | [T: 8201, S: 60] |
| 310 | | seek | | 8201 | | 45 | | 60 | | |
| 494 | | rotate | | 8201 | | 62 | | 60 | | |
| 640 | | read | | 8201 | | 60 | | 60 | | |
| 640 | | DONE | | | | 61 | | | | |
Problem 4 Producer-Consumer
Your producer-consumer used synchronization primitives to manage a buffer. Outline a system with three identical producers and one consumer using message-passing primitives msg_send() and msg_recv().
- Sketch some appropriate diagram.
- Give pseudo code for the producers.
- Give pseudo code for the consumer.
- List assumptions you make about msg_send() and msg_recv(). (That is a hint.)
- Explain how your solution works.
- Does your solution provide mutual exclusion? If so, how? If not, why is mutual exclusion not required?
There are MANY possible designs.
Perhaps the most obvious to you is to have a buffer manager process that works the same way as the shared memory version, except using messages instead of shared memory
Perhaps the easiest solution is to make strong assumptions on the capabilities of msg_send() and msg_recv(), for example:
- OS enforces a strict queue discipline on message queues.
- OS implementation of msg_send() is thread-safe. That is, the OS cannot execute two calls to msg_send() concurrently, probably by having all msg_send() requests executed by one process, so it cannot do more than one. This provides mutual exclusion.
- msg_send() blocks until there is space in the queue (but not until its message is received). Alternatively, you could assume msg_send() returns >= 0, if its message is enqueued, < 0 if not, for example if the queue is full.
- msg_recv(..., 'WAIT') blocks until there is a message to receive.
Those are all reasonable assumptions for real operating systems.
Producer:
while (true)
{
/* Produce an item into nextProduced */
msg_send(CONSUMER, nextProduced);
}
|
|
Consumer:
while (true)
{
msg_recv(nextConsumed, 'WAIT');
/* Consume item in nextConsumed */
}
|
It does not matter how many producers there are.
If your solution does not provide mutual exclusion, it does not work.
Problem 5 Internet Protocols
Choose ONE of a or b:
- Explain how Domain Name Service (DNS) works.
Your explanation should cover DNS in general. Your explanation should include:
- What is the purpose?
- Draw an appropriate sketch illustrating the process.
- What information do you start with (input)?
- What is the end result (output)?
- How is the output derived from the input?
- How are changes in the world reflected?
OR
- Explain how routing works.
Your explanation should cover routing in general. Your explanation should include:
- What is the purpose?
- Draw an appropriate sketch illustrating the process. Your sketch might include a source, a destination, and 2-3 intermediate gateways.
- What information do you start with (input)?
- What is the end result (output)?
- What happens at each of the 4-5 machines in your sketch?
- See Section 16.5.1, Lecture notes on DNS,
or HowStuffWorks, How Domain Name Servers Work
- See Section 16.5.2 Routing Strategies or Lecture notes on Routing
Problem 6 Caching
The concept of caching has arisen many times, in several different contexts, in our study of computer operating systems.
- Explain "caching" as a concept.
- List five different contexts in which we have seen caching in this class.
Hint: "different contexts" means "different chapters of our text."
For each of your five different contexts, draw a diagram and explain how caching works in that context.
- What are the advantages of caching?
- [Inadvertently left off the exam] What are the disadvantages of caching?
- Caching concerns the hierarchy of memory. Caching means that we keep a local copy of some frequently accesses information of interest in a memory mechanism closer to our processor than its original source to gain speed. Typically, the cache is relatively close, relatively small, relatively fast, and relatively expensive. The source is relatively remote, relatively large, relatively slow, and relatively cheap.
See Sections 1.8.3,
- Your answer might include:
- Level 1, 2, & 3 cache: Near - hardware cache memory; Far - main memory
- Virtual memory: Near - main memory; Far - disk
- Page table: Near - TLB; Far - main memory
- Reading file from disk: Near - buffer disk controller; Far - disk
- Reading file from disk: Near - buffer in main memory; Far - disk
- Domain Name Service: Near - memory of file on local server; Far - remote server
- HTTP: Near - browser memory; Far - remote server
- HTTP: Near - local server; Far - remote server
- Distributed File System: Near - local disk; Far - remote server
- Speed, redundancy, reduced bus traffic, low cost
- Complexity of cache management, need to manage redundancy to maintain consistency
Problem 7 [OMITTED] TCP/IP Protocol Architecture
List the four layers of the DoD communications stack. Draw a diagram illustrating the communications stack. For each layer,
- Give the name of the layer
- What is its purpose?
- List at least one protocol that implements this layer.
- The Network Access Layer is responsible for delivering data over the particular
hardware media in use. Different protocols are selected from this layer, depending
on the type of physical network. Protocols: Ethernet, wireless
- The Internet Layer is responsible for delivering data across a series of different
physical networks that interconnect a source and destination machine. Routing
protocols are most closely associated with this layer, as is the IP Protocol, the
Internet's fundamental protocol.
- The Host-to-Host Layer handles connection rendezvous, flow control,
retransmission of lost data, and other generic data flow management. The mutually
exclusive TCP and UDP protocols are this layer's most important members.
- The Process Layer contains protocols that implement user-level functions, such as
mail delivery, file transfer and, remote login.
| |