| |
Your second midterm examination will appear here. It covers Chapters 5-7 & 10.
It will be a 50 minute, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Section and page number references in old exams refer to the edition of the text in use when that exam was given. You may have to do a little looking to map to the edition currently in use. Also, which chapters were covered on each exam varies a little from year to year.
Questions will be similar to homework questions from the book. You will
be given a choice of questions.
I try to ask questions I think you might hear in a job interview. "I
see you took a class on Operating Systems. What can you tell me about ...?"
Preparation hints:
Read the assigned chapters in the text. Chapter summaries are especially helpful. Chapters 1 and 2 include excellent summaries of each of the later chapters.
Read and consider Practice Exercises and Exercises at the end of each chapter.
Review authors' slides and study guides from the textbook web site
Review previous exams listed above.
See also Dr. Barnard's notes. He was using a different edition of our text, so chapter and section numbers do not match, but his chapter summaries are excellent.
Results on exam 1 suggest you may wish to maintain a vocabulary list.
Read and follow the directions:
- Write on four of the five questions. If you write more than four questions, only the first four will be graded. You do not get extra credit for doing extra problems.
- In the event this exam is interrupted (e.g., fire alarm or bomb threat), students will leave their papers on their desks and evacuate as instructed. The exam will not resume. Papers will be graded based on their current state.
- Read the entire exam. If there is anything you do not understand about a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of paper [or -5].
- Be sure your name is on each sheet of paper you hand in [or -5]. That is because I often separate your papers by problem number for grading and re-assemble to record and return.
- Write only on one side of a sheet [or -5]. That is because I scan your exam papers, and the backs do not get scanned.
- No electronic devices of any kind are permitted.
- Be sure I can read what you write.
- If I ask questions with parts
- . . .
- . . .
your answer should show parts
- . . .
- . . .
Score Distribution:
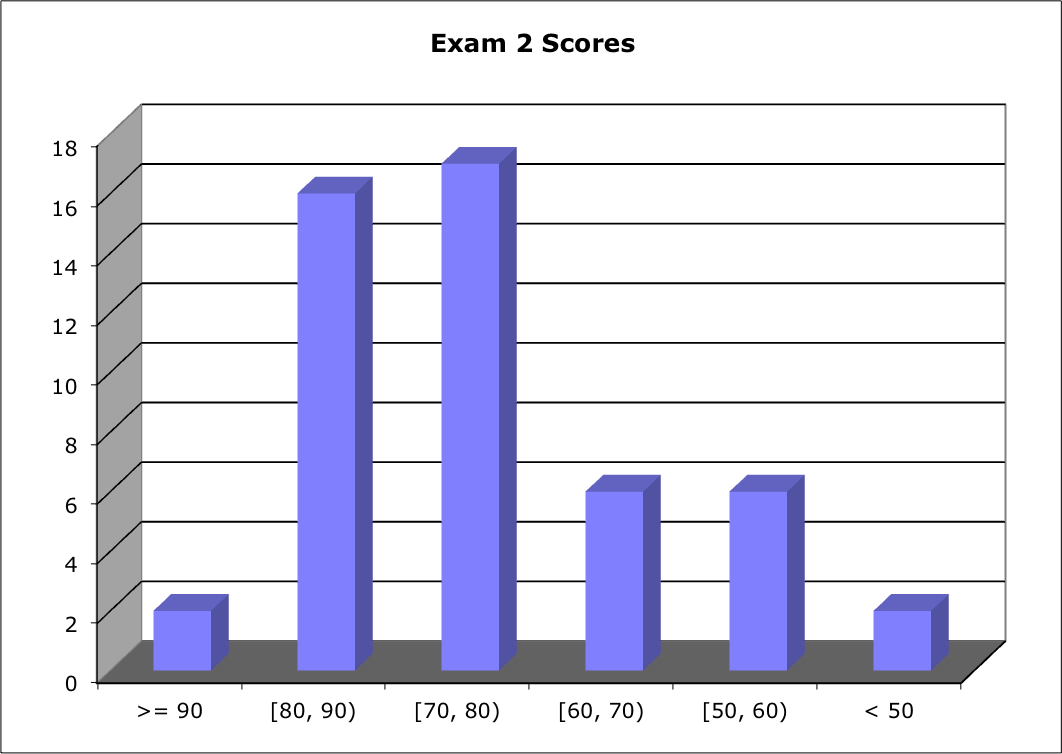
Median: 73; Mean: 71.6; Standard Deviation: 21.0
These shaded blocks are intended to suggest solutions; they are not intended to be complete solutions.
Several of these questions ask you to apply what you know to unfamiliar problems.
Solution outlines are likely to be refined as the exams are graded.
Problem 1 Definitions
Problem 2 Mutual Exclusion
Problem 3 Dining Philosophers
Problem 4 Advanced Message Passing
Problem 5 Disk Scheduling for Solid State Drives
Problem 1 Definitions
Give careful definitions for each term (in the context of computer operating systems):
- A solution to the critical-section problem must satisfy what three requirements?
- A deadlock satisfies what four necessary conditions? Explain each.
- Compare and contrast NAS and SAN ("S" = Storage). What are the similarities and the differences? What are the advantages and disadvantages?
- Compare and contrast SSTF and C-SCAN for hard disk scheduling. What are the similarities and the differences? What are the advantages and disadvantages?
- Compare and contrast error-correcting codes and encryption codes (e.g., public key cryptography). What are the similarities and the differences?
Hint: "Compare and contrast A and B" should be a familiar template for examination questions in many fields. Your response should take the form:
Define A
Define B
How are A and B similar? (compare)
How are A and B different? (contrast)
Specific questions were chosen from this collection:
- Critical-Section problem [p. 206] solution must provide mutual exclusion, must allow each process to make progress, and must ensure the time a process must wait to enter its critical section is bounded.
- Deadlock necessary conditions [p. 318]: Mutual exclusion, Hold and wait, No preemption, Circular wait.
"Wait ON" vs. "Wait FOR." One waits ON superiors, to take care of, or to serve; e.g., a store clerk waits ON customers. One waits FOR peers, e.g., you might wait for a friend to go to the lab. A server process might be said to "wait on" a client process, but process scheduling, mutual exclusion, deadlock, etc., involve processes waiting FOR each other.
- NAS = Network-Attached Storage [p. 471]; SAN = Storage-Area Network [p. 472].
- SSTF = Shortest-seek-time-first [p. 474]; C-SCAN [p. 476].
- Error-correcting code [p. 479]: Encoding data is such a way that a certain number of errors can be detected and a (smaller) number of errors can be corrected. (Circular statements such as "Error-correcting codes are codes for correcting errors" received zero points.) Encryption codes protect against unauthorized access.
- Cooperating process [p. 203]: One that can affect or be affected by other processes executing in the system.
- Race condition [p. 205]: Several processes access and manipulate the same data concurrently, and the outcome of the execution depends on the particular order in which the accesses take place.
- Atomic execution [p. 210]: An instruction is implemented as one uninterruptable unit.
- Deadlock [p. 217]: Two or more processes are waiting indefinitely for an event that can be caused only by one of the waiting processes.
- Starvation [p. 217]: A process may wait indefinitely.
- Priority inversion [p. 217]: A high priority process is forced to wait for a lower priority process to release some resource(s).
- CPU-I/O burst cycle [p. 262]: Processes typically alternate between periods of high CPU activity and periods of high I/O activity
- Rate-monotonic real-time CPU scheduling [p. 287]: Upon entering the system, each periodic task is given a static priority inversely based on its period. If a lower priority process is running, and a higher priority process becomes available to run, the lower priority process is interrupted.
- Proportional share real-time CPU scheduling [p. 289]: Allocate T shares among all applications. An application can receive N shares of time, ensuring that the application is allocated N/T of the total processor time.
Problem 2 Mutual Exclusion
Suppose we provide mutual exclusion locks in software. A process that attempts to acquire an unavailable lock is blocked until the lock is released:
acquire() {
while (!available); /* busy wait */
available = false;
}
The definition of release():
release() {
available = true;
}
Describe what changes would be necessary so that the process waiting to acquire a mutex lock would be blocked and placed into a waiting queue until the lock became available.
Problem 5.16, p. 245.
Your solution should describe a process similar to the manner in which your homework handled messages.
We should create a new queue meQueue.
In acquire():
acquire() {
if (!available) {
enqueue(meQueue, thisProcess);
resched();
}
available = false;
}
In release():
release() {
if (!isEmpty(meQueue) {
move process at head of meQueue to Ready state;
}
available = true;
}
If a process is waiting, it cannot execute code.
A solution that retained busy wait was seriously penalized.
Alternatively, use the existing semaphore primatives.
This is not a scheduling problem.
I expected sufficient detail that a classmate who did not know what to do could follow your instructions to a successful solution. In particular, you must explain how a waiting process gets un-blocked. Scores depended primarily on the level of detail you provided. In general, it took pseudo-code to earn a score > 20.
Problem 3 Dining Philosophers
- Design a solution to the Dining Philosophers Problem with four philosophers.
- Convince me that your solution enforces exclusive access to chopsticks.
- Convince me that your solution prevents deadlock.
Hint: Part of the problem is to recognize what properties a "solution" must have.
There are MANY different ways to approach the solution. The easiest solutions to the Dining Philosophers Problem probably employ a matre'd process who must give permission. Alternatively, it is enough to put the code for picking up both chopsticks (not the eating) in one critical section. Neither of those scale well to hundreds of philosophers, but the problem does not require that.
Introducing a 5th chopstick solves this problem, but may not be feasible in an OS context.
Odd numbered philosophers pick up right, then left; even numbered philosophers pick up left, then right. In an OS context, you prefer each process runs the same code.
Giving each philosopher a priority or enforcing some other order can work, but enforcement of proposed protocols is not trivial.
It works to have only philisophers on opposite sides of the table eating at once, but enforcing that is not trivial.
If a request for a second chopstick is denied, the philosopher must relenquish the first. Works here, but could be catestrophic in an OS context.
Variant: Allow preemption or put the first chopstick back on the table, but only after a specified time. It does NOT help to make eating time out.
You can enforce an order among resources, but that does not scale well.
Some solutions are prone to race conditions.
A philosopher who is eating is NOT contributing to deadlock. Although obesity may be a growing problem, eating is not part of the problem here.
ALL solutions are less than idea when carried over to an OS context.
"Convince me" is a high bar. One example that works is not sufficient.
Ideally, you solution works not just for philosophers and chopsticks, but also for OS processes and resources. The problem is interesting to the extent it helps us understand operating systems issues, not because philosophers are hard to feed.
Problem 4 "Advanced" Message Passing
What extensions would be required in your solution to the mailboxes Assignment 7 to allow
- lengths of message bodies to be potentially large? Explain.
- multiple messages to be sent, but not yet received? Messages should wait for respective recipients to recv() them? Explain.
- a function syscall sendtime(int pid, message, time); that mirrors message recvtime(time);.
Case i) If the intended recipient is blocked waiting to receive a message, sendtime() should unblock that process and reschedule.
Case ii) If the intended recipient is NOT waiting to receive a message, sendtime() should block the sending process for the specified time and reschedule.
Hint: You may need to provide additional specifications for sendtime() to make it behave as a logical mirror of recvtime()
- Larger message bodies can be accommodated easily by expanding the size
of the message field in the process control block from a single integer
to an array of bytes or integers. However, this has the obvious
disadvantage
of bloating the fixed-size table of process control blocks in our embedded
operating system, which may not be an appropriate trade-off unless large
messages are required frequently. Moreover, statically declared message
arrays will still have a fixed upper bound for message sizes, which may not
make sense if maximum message size is not known.
Alternatively, the message system could be altered to use a single
pointer field in the process control block to pass a pointer to a
dynamically
allocated message array. This addresses the two limitation discussed above,
but raises its own issues in terms of responsibility for freeing the message
space. We can easily share dynamically allocated space between processes
in Embedded Xinu, but a production O/S would have memory protection
and/or virtual memory barriers in place that would make it difficult to
share such message buffers between separate processes easily. In this case,
the O/S is often responsible for ferrying the memory space for the message
between process address spaces, which can be a time-consuming operation.
- Much like part a), for part b), we can employ an array of slots in the
process control block, where each slot can hold a single message. The
message passing system then needs a mechanism to track how many message
slots are filled for each process, as well as a means if identifying the
next message in a circular queue or other data structure.
- The current send() function does not block, and either sends a message
immediately, or returns SYSERR because the destination already has a
message.
Case (i) sendtime() is the same as the existing send() in the case
when (PRRECV == ppcb->state).
For case (ii), sendtime() would work much like recvtime(), placing the
sending process onto the delta queue, and setting its process state to a new
value. What is new here is that all three of the recv() variants would
need to know 1) which process or processes were waiting to send, and 2)
how to awake one of those processes from the sleep queue.
If an arbitrary number of processes are allowed to call sendtime() with
the same intended recipient process, this gets quite elaborate. Then
the process control block needs to have a per-process queue of blocked
senders
waiting their turns, which could be proportional to the total number of
processes in the worst case. For the sake of maintaining some semblance of
Xinu's simplicity, we would probably want to limit sendtime() to allowing
at most one process to block on a single receiver.
Assuming all of this worked, this is still a terrible message-passing
scheme. A sending process that runs first blocks, waiting for the receiver
process to run. Once the receiver process runs, it has to awaken the sender
from its slumber when it calls recv(). Then the sender process must run
again to actually deliver the message. Finally, the receiver must run again
to receive the message. Considering the implications of priority- and
age-based scheduling in the system, it is hard to see how messages would
ever
get delivered effectively within tight timeout limits.
Problem 5 Disk Scheduling for Solid State Drives
In class and in the text, we discussed several scheduling strategies for hard disk reads and writes.
- What strategies would you recommend for scheduling reads from solid state drives? Explain.
- What strategies would you recommend for scheduling writes to solid state drives? Explain.
- What strategies would you recommend for scheduling a mixed stream of about 90% reads and 10% writes from/to solid state drives? Explain.
There's little advantage in reordering read requests, but
significant advantage in coalescing adjacent write requests to reduce the
number of erase block operations.
- Because SSDs have no physical arm to move, there is little advantage
to reordering read requests. FCFS is probably quite effective.
- Scheduling write requests to an SSD is a different matter. Because
of the high costs of erasing a large block to write to the drive,
there is significant advantage to a write ordering strategy that coalesces
nearby write requests into a single erase and write operation. This will
also help with wear-leveling by reducing the number of erase cycles
on commonly written blocks. This doesn't really look quite like any of
the magnetic disk scheduling algorithms discussed in class, but is easy
enough to describe using a bucket queue or a simple cache structure.
- For a mixed stream of reads and writes to an SSD, it seems clear
that the reads and writes should be scheduled separately, with simple
FCS for reads, and a coalescing scheduler for writes. The hardest part
is accounting for out-of-order semantics for reads that are issued after
corresponding writes. Again, a cache structure seems like one reasonable
solution.
Many missed the implications of out-of-order execution. This can be a serious problem on disks, too. If the application writes something, then reads it, but the storage schedule reverses the order (read, then write), the application can receive incorrect information. You can give writes priority over reads, which defeats the intent of part b), or you can use a cache, with reads first checking the cache.
Algorithms such as LOOK, SCAN, or CSCAN make no sense, since there are no moving parts. SJF makes no sense, since all reads are the same, and all writes are the same.
Not used in this exam:
CPU Scheduling
Consider the following set of processes, with the length of the CPU burst given in milliseconds:
| Process | Burst time | Priority |
|---|
| P1 | 2 | 2 |
| P2 | 1 | 1 |
| P3 | 8 | 4 |
| P4 | 4 | 2 |
| P5 | 5 | 3 |
- Draw four Gantt charts that illustrate the execution of these processes using the following scheduling algorithms: FCFS, SJF, nonpreemptive priority (a larger priority number implies a higher priority), and RR (quantum = 2).
- What is the turnaround time of each process for each of the scheduling algorithms in part a)?
- What is the waiting time for each process for each of the scheduling algorithms in part a)?
- Which of the algorithms results in the minimum average waiting time (over all processes)?
Problem 6.16, p. 308.
No spinlock
The Linux kernel enforces a policy that a process cannot hold a spinlock (e.g., while (!available);) while attempting to acquire a semaphore. Explain why this policy is in place.
Problem 5.12, p. 244.
| |