| |
Your second midterm examination will appear here. It covers Chapters 6 - 12.
It will be a 50 minute, closed book exam.
Expectations:
- See course goals and objectives
- See Objectives at the beginning of each chapter
- See Summary at the end of each chapter
- Read, understand, explain, and desk-check C programs
-
See previous exams:
Section and page number references in old exams refer to the edition of the text in use when that exam was given. You may have to do a little looking to map to the edition currently in use. Also, which chapters were covered on each exam varies a little from year to year.
Some questions may be similar to homework questions from the book. You will be given a choice of questions. I try to ask questions I think you might hear in a job interview. "I see you took a class on Operating Systems. What can you tell me about ...?"
Preparation hints:
Read the assigned chapters in the text. Chapter summaries are especially helpful. Chapters 1 and 2 include excellent summaries of each of the later chapters.
Read and consider Practice Exercises and Exercises at the end of each chapter.
Review authors' slides and study guides from the textbook web site.
Review previous exams listed above.
See also Dr. Barnard's notes. He was using a different edition of our text, so chapter and section numbers do not match, but his chapter summaries are excellent.
Read and follow the directions:
- Write on four of the five questions. If you write more than four questions, only the first four will be graded. You do not get extra credit for doing extra problems.
- Each problem is worth 25 points.
- In the event this exam is interrupted (e.g., fire alarm or bomb threat), students will leave their papers on their desks and evacuate as instructed. The exam will not resume. Papers will be graded based on their current state.
- Read the entire exam. If there is anything you do not understand about a question, please ask at once.
- If you find a question ambiguous, begin your answer by stating clearly what interpretation of the question you intend to answer.
- Begin your answer to each question at the top of a fresh sheet of paper [or -5].
- Be sure your name is on each sheet of paper you hand in [or -5]. That is because I often separate your papers by problem number for grading and re-assemble to record and return.
- Write only on one side of a sheet [or -5]. That is because I scan your exam papers, and the backs do not get scanned.
- No electronic devices of any kind are permitted.
- Be sure I can read what you write.
- If I ask questions with parts
- . . .
- . . .
your answer should show parts in order
- . . .
- . . .
- The instructors reserve the right to assign bonus points beyond the stated value of the problem for exceptionally insightful answers. Conversely, we reserve the right to assign negative scores to answers that show less understanding than a blank sheet of paper. Both of these are rare events.
The university suggests exam rules:
- Silence all electronics (including cell phones, watches, and tablets) and place in your backpack.
- No electronic devices of any kind are permitted.
- No hoods, hats, or earbuds allowed.
- Be sure to visit the rest room prior to the exam.
In addition, you will be asked to sign the honor pledge at the top of the exam:
"I recognize the importance of personal integrity in all aspects of life and work. I commit myself to truthfulness, honor and responsibility, by which I earn the respect of others. I support the development of good character and commit myself to uphold the highest standards of academic integrity as an important aspect of personal integrity. My commitment obliges me to conduct myself according to the Marquette University Honor Code."
Name _____________________________ Date ____________
Raw Score Distribution:
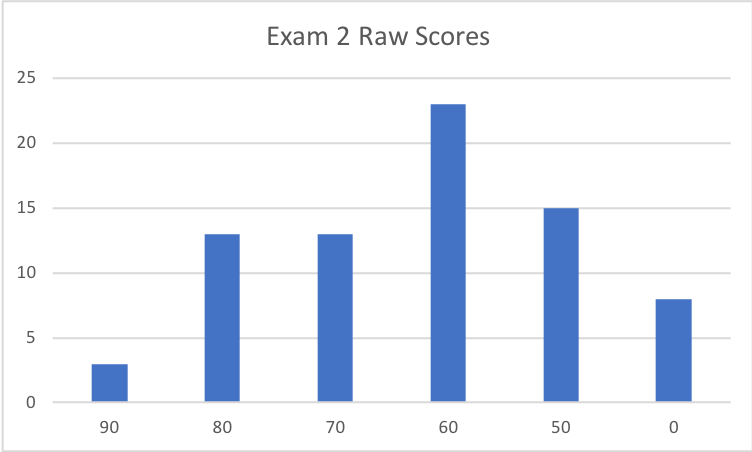
Median: 66; Mean: 66.5; Standard Deviation: 15.4
Average is 3.6 points higher than Exam 1
Added 5 point bonus to everyone's score.
These shaded blocks are intended to suggest solutions; they are not intended to be complete solutions.
Problem 1 Vocabulary
Problem 2 Is "Starvation" Fake News?
Problem 3 Dining Philosophers
Problem 4 Disk Scheduling for Solid State Drives
Problem 5 Tricky C
Problem 1 Vocabulary
Give careful definitions for each term (in the context of computer operating systems):
- A solution to the critical-section problem must satisfy what three requirements?
- A deadlock satisfies what four necessary conditions? Explain each.
- Compare and contrast SSTF and C-SCAN for hard disk scheduling. What are the similarities and the differences? What are the advantages and disadvantages?
- Compare and contrast direct and indexed file access strategies. What are the similarities and the differences? What are the advantages and disadvantages?
Hint: "Compare and contrast A and B" should be a familiar template for examination questions in many fields. Your response should take the form:
Define A
Define B
How are A and B similar? (compare)
How are A and B different? (contrast)
6 points for each part.
- Critical-Section problem [p. 206] solution must provide mutual exclusion,
must allow each process to make progress, and must ensure the time a process must wait to enter its
critical section is bounded.
- Deadlock necessary conditions [p. 318]: Mutual exclusion, Hold and wait, No preemption, Circular wait.
"Wait ON" vs. "Wait FOR." One waits ON superiors, to take care of, or to serve; e.g., a store clerk waits ON customers. One waits FOR peers, e.g., you might wait for a friend to go to the lab. A server process might be said to "wait on" a client process, but process scheduling, mutual exclusion, deadlock, etc., involve processes waiting FOR each other.
- SSTF = Shortest-seek-time-first [p. 474]; C-SCAN [p. 476]. These are algorithms for
disk scheduling, as the problem says, not process scheduling.
- See Section 11.2.2. Both apply to reading or writing fixed-length logical records
within a file in no particular order. They are not about accessing one file among many.
Both assume the file being accessed is a large collection of equal-length records, like records in a database. These access methods were developed in the 1960's when files were essentially collections of 80-column cards. If each record is the same length, consecutive records reside in the same disk block. Just for the sake of illustration, assume 16 records fit on one disk block.
For "direct," think of array indexing. If I want record number 4325, it is on the 270th disk block (4325 / 16 = 270.3125), and it is the 5th record in that block. Hence, I retrieve the 270th disk block in the file (at whatever disk address it happens to lie), and read or write the 5th record. Point: Access complexity is O(1).
But, how did we know the record we wanted was number 4325? That's where "indexed" access comes in. If the file holds a table from a database, it has one of more indexed (in the database sense) columns. For example, suppose MUID is a primary key, and we want to find student #000791525. The database engine "knows" that student #000791525 is the 4325th record, using a hash function. Hence, we can find MUID 000791525 in time O(1). No search.
Direct and indexed access are the province of the application, the operating system, and the disk
controller, not the user.
Problem 2. Is "Starvation" Fake News?
While starvation is a theoretical threat, it is not a threat in practice. A good scientist might worry, but a good engineer can fix it. Sure, it is possible for a process to be starved in a ready list or a disk request to be starved in a disk controller. If we experience starvation, the list of pending work probably just keeps getting longer. In practice, however, if our CPU or our disk controller has so much work to do that some task never completes, we need either a) faster hardware or b) less work. Solved problem.
Do you agree or disagree with this paragraph? Why?
Hints: Is "starvation" a real or a fake threat? Your answer should exhibit your depth of understanding of scheduling issues. How can starvation occur in CPU scheduling or disk access scheduling? Bonus if you give another (operating systems) example of starvation? If one task experiences starvation, what else is going on? Is the user community pleased with this system as a whole? Can an engineer really make starvation disappear with faster hardware? Can an engineer really make starvation disappear with less work? Are there other solutions? How does the availability of multiple cores affect your answer? You might draw on experiences from some of your homework testing.
"Yes" and "No," of course. It is true that in a heavily loaded system, if one task never
gets a chance, the computer is not keeping up with its work load, and the problem is worse
than "starvation" might suggest. Faster hardware or less work are two solutions.
Or a better algorithm. It might be that if we are smarter at managing
CPU time (e.g., longer quantum for less time wasted in context swap?) or disk scheduler
(e.g., CSCAN or C-Look vs. SSTF?), we might be able to keep up.
Faster hardware or less work threaten your job, but smarter algorithms is an opportunity.
That's what I wrote when I prepared the exam. After reading your answers, I want to be more
forceful. Nearly all of you have drunk too deeply from the academic Kool-Aid; you could stand to
be more skeptical of what you are told.
Yes, starvation can be a real problem, and, yes, aging can prevent starvation. True, but
starvation is not the real problem.
But when I was a young faculty member, a kindly grizzled, old (probably 45) OS practitioner
called me out.
That's correct, but it entirely misses the point. THINK about it. If you have
a process or a disk request that is never getting served, what else is going on? Many
other processes or requests are piling up behind it. Getting that request served is the
least of your problems. What is really going on is that you can't keep up with your
work load, and no aging will fix that. If your system is experiencing starvation, you have
FAR MORE SERIOUS problems to deal with.
Grading? Whether you said "Agree" or "Disagree" made no difference in your grade. A good discussion
of starvation, the realities of starvation, and solutions such as aging earned ≤ 20 points.
To earn more points, you needed some recognition of the reality of work piling up behind the
starving request.
If assignments experience starvation (never getting done) in your personal time management, what solutions
are possible? Work smarter? That's a faster machine or more cores. Say "No" to some requests
for time? That's accept less work. Do a poor job on some assignments? I'm not sure what to call
the OS equivalent of that. Perhaps you work for a predetermined time, and then you stop?
I worked on a project once. The first time we ran the full system took 43 hours to run daily reports.
The plant manager would not give us a second mainframe, so we cut the scope of the reports in half.
Sometimes, you can get by with less work, when other alternatives are infeasible.
Multiple cores? That essentially a faster machine, which may provide the horsepower to keep up
with the work stream.
Yes, with FIFO, no one is starved, but the queue may become unbounded, too.
Problem is a poor scheduling algorithm? Yes, it may be that a smarter process or disk
scheduling algorithm may increase throughput, and can eliminate starvation, it may not
empty the quere of ready requests.
Starvation resulting from deadlock is no issue -- The issue is the deadlock.
A process being indefinitely in a "wait" state is not starvation -- That's bad system design,
possibly, but not necessarily, deadlock.
Please do not be offended by "scientist" and "engineer." In this context, my "scientist"
represents the thinker, and my "engineer" represents the doer. Both are essential.
Problem 3 Dining Philosophers
- Design a solution to the Dining Philosophers Problem with four philosophers.
- Convince me that your solution enforces exclusive access to chopsticks.
- Convince me that your solution prevents deadlock.
Hint: Recognize that each philosopher is analogous to one core in a four-core system. Part
of the problem is to recognize what properties a "solution" must have. This question is
not really about philosophers. Consider OS implications.
There are MANY different ways to approach the solution. The key is that a philosopher
gets two chopsticks, or he gets none. You must ensure that with no race conditions.
Avoiding race conditions (using mutual exclusion to protect your bookkeeping) is as
important as avoiding deadlock.
The easiest solutions to the Dining Philosophers Problem probably employ a matre'd process who must give permission. Alternatively, it is enough to put the code for picking up both chopsticks (not the eating) in one critical section. Neither of those scale well to hundreds of philosophers, but the problem does not require that.
You should make no assumptions about the order in which the philosophers might be hungry.
Any solution requires some form of mutual exclusion (or -8 points). How do you enforce mutual exclusion?
Mutual exclusion does not have to protect eating or chopsticks; it protects the bookkeeping
of who has which chopsticks.
The textbook solution encloses picking up both chopsticks in a critical section. When a
philosopher wishes to eat, he requests to enter the critical section. If both chopsticks
are available, he picks them up, exits the critical section, and eats. Using the
chopsticks is not a critical section. Placing the chopsticks back
on the table also is a critical section.
If you propose round-robin scheduling, it should be of philosophers' requests to eat because
you should not assume an order in which they'll want to eat. How does round-robin scheduling
enforce mutual exclusion and avoid race conditions?
A monitor is a convenient means to enforce mutual exclusion.
Introducing a 5th chopstick solves this problem, but may not be feasible in an OS context.
Odd numbered philosophers pick up right, then left; even numbered philosophers pick up left, then right. In an OS context, you prefer each process runs the same code.
Giving each philosopher a priority or enforcing some other order can work, but enforcement of proposed protocols is not trivial.
It works to have only philosophers on opposite sides of the table eating at once, but enforcing that is not trivial.
If a request for a second chopstick is denied, the philosopher must relinquish the first. Works here, but could be catastrophic in an OS context.
Variant: Allow preemption or put the first chopstick back on the table, but only after a specified time. It does NOT help to make eating time out.
Preemption? Suppose that if I have one chopstick (say left), and the right one is
not available, I can take it from my neighbor to the right. Does that work? NO.
If all four philosophers have picked up their left chopstick simultaneously, each simultaneously
preempts the philosopher to their right. That means simultaneously, the philosopher to
their left preempts the chopstick they were holding. Hence, everyone is holding their
right chopstick, so they preempt the chopstick to their left. Sounds like a fight!
You can enforce an order among resources, but that does not scale well.
Most solutions are prone to race conditions.
A philosopher who is eating is NOT contributing to deadlock. Although obesity may be a growing problem, eating is not part of the problem here.
ALL solutions are less than ideal when carried over to an OS context.
Does your solution allow two facing philosophers to eat at the same time?
"Convince me" is a high bar. One example that works is not sufficient.
Ideally, you solution works not just for philosophers and chopsticks, but also for OS processes and resources. The problem is interesting to the extent it helps us understand operating systems issues, not because philosophers are hard to feed.
Problem 4 Disk Scheduling for Solid State Drives
In class and in the text, we discussed several scheduling strategies for hard disk reads and writes.
- What strategies would you recommend for scheduling reads from solid state drives? Explain.
- What strategies would you recommend for scheduling writes to solid state drives? Explain.
- What strategies would you recommend for scheduling a mixed stream of about 90% reads and
10% writes from/to solid state drives? Explain.
- How does it matter that read or write requests may be coming from multiple cores?
6 points each.
Scheduling is about the order in which pending reads or writes are executed.
The disk controller has a collection of pending read requests and write requests. In which order
should it perform them?
This question also is not about sequential, direct, or index file access strategies.
Fit? Reading has nothing to do with fitting, first, worst, or best. For writing
at the disk controller level, we are writing blocks. Fitting logical blocks in the
same write block is a factor, but this question is about scheduling the order of reads
and writes, but about deciding where they should go.
There is little advantage in reordering read requests, but
significant advantage in coalescing adjacent write requests to reduce the
number of erase block operations.
- Because SSDs have no physical arm to move, there is little advantage
to reordering read requests. FCFS is probably quite effective.
- Scheduling write requests to an SSD is a different matter. Because
of the high costs of erasing a large block to write to the drive,
there is significant advantage to a write ordering strategy that coalesces
nearby write requests into a single erase and write operation. This will
also help with wear-leveling by reducing the number of erase cycles
on commonly written blocks. This doesn't really look quite like any of
the magnetic disk scheduling algorithms discussed in class, but is easy
enough to describe using a bucket queue or a simple cache structure.
- Should maintain read/write semantics. That is, if the disk controller receives a read
before a write to the same location (or a write before a read), we do not have to execute
them in the order they were received, but the results must be the same as if we did.
For a mixed stream of reads and writes to an SSD, it seems clear
that the reads and writes should be scheduled separately, with simple
FCS for reads, and a coalescing scheduler for writes. The hardest part
is accounting for out-of-order semantics for reads that are issued after
corresponding writes. Again, a cache structure seems like one reasonable
solution.
Many missed the implications of out-of-order execution. This can be a
serious problem on disks, too. If the application writes something, then reads it, but
the storage schedule reverses the order (read, then write), the application can receive
incorrect information. You can give writes priority over reads, which defeats the intent
of part b), or you can use a cache, with reads first checking the cache.
- Probably not at all. By the time requests get to the disk controller where they are
scheduled, there is no need for mutual exclusion.
Multiple cores will not make the SSD faster. Squirrel!
Algorithms such as SSTF, LOOK, SCAN, or CSCAN make no sense, since there are no moving parts.
SJF makes no sense, since all reads are the same, and all writes are the same.
Problem 5 Tricky C
Consider the following code:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 struct listnode
5 {
6 int payload;
7 struct listnode *next;
8 struct listnode *prev;
9 };
10
11 /* function prototypes */
12 int enqueue(int, struct listnode*);
13 void findpid(int, struct listnode*);
14
15 int main()
16 {
17 struct listnode *head;
18 head = (struct listnode*)malloc(sizeof(struct listnode));
19 if (head == NULL)
20 {
21 fprintf(stderr, "Not Enough Memory!\n");
22 exit(EXIT_FAILURE);
23 }
24 head->prev = NULL;
25 head->payload = -1;
26 head->next = NULL;
27
28 int pid;
29 for (pid = 0; pid < 5; pid++)
30 enqueue(pid, head);
31
32 findpid(5, head);
33
34 return EXIT_SUCCESS;
35 }
36
37 int enqueue(int pid, struct listnode *head)
38 {
39 struct listnode *current;
40 struct listnode *newnode;
41
42 if (head->payload == -1)
43 {
44 head->payload = pid;
45 }
46 else
47 {
48 current = head;
49 while (current->next != NULL)
50 current = current->next;
51
52 newnode = (struct listnode*)malloc(sizeof(struct listnode));
53 if (newnode == NULL)
54 {
55 fprintf(stderr, "Not Enough Memory!\n");
56 exit(EXIT_FAILURE);
57 }
58 current->next = newnode;
59 newnode->prev = current;
60 newnode->payload = pid;
61 newnode->next = NULL;
62 }
63 return pid;
64 }
65
66 void findpid(int pid, struct listnode *head)
67 {
68 struct listnode* current = head;
69 while (current->payload != pid) {
70 printf("Looking at process %d.\n", current->payload);
71 current = current->next;
72 }
73
74 if (current->payload == pid)
75 printf("Found process %d!\n", pid);
76 else
77 printf("Process %d not found.\n", pid);
78 }
- Draw a picture of the data structure pointed to by the "head" pointer.
- What does the program output when run as-is?
- If working properly, the last line of output should read "Process 5 not found." Modify the source code accordingly.
Hint: correct answers should maintain functionality for other process IDs and processes that actually are found, and not just hack it for this particular run.
- The struct members in this code are accessed via pointers (ex. current, newnode) because the nodes are allocated dynamically with malloc. In your Xinu operating system, the queues are statically allocated.
What is the major difference between the way struct members are accessed in these two approaches?
Hint: What operator needs to change? To what should it be changed?
- A sketch of a doubly linked list with 5 nodes, where head points to the first node, and the tail points to NULL.
Looking at process 0.
Looking at process 1.
Looking at process 2.
Looking at process 3.
Looking at process 4.
Segmentation fault - See commented section of line 69. (Remove for provided code)
69 while (current->payload != pid && current->next != NULL) {
- Change arrow operator (->) to (.).
| |